
זיהוי דיבור אוטומטי (ASR) עבר כברת דרך. למרות שהוא הומצא לפני זמן רב, הוא כמעט ולא היה בשימוש על ידי אף אחד. עם זאת, הזמן והטכנולוגיה השתנו כעת באופן משמעותי. תמלול אודיו התפתח באופן מהותי.
טכנולוגיות כגון AI (בינה מלאכותית) הניעו את תהליך תרגום אודיו לטקסט לתוצאות מהירות ומדויקות. כתוצאה מכך, גם היישומים שלה בעולם האמיתי גדלו, כאשר כמה אפליקציות פופולריות כמו Tik Tok, Spotify ו-Zoom הטמיעו את התהליך באפליקציות הנייד שלהם.
אז תן לנו לחקור את ASR ולגלות מדוע היא אחת הטכנולוגיות הפופולריות ביותר בשנת 2022.
מה זה דיבור לטקסט?
דיבור לטקסט היא טכנולוגיה משופרת בינה מלאכותית המתרגמת דיבור אנושי מאנלוגי לצורה דיגיטלית. יתר על כן, הצורה הדיגיטלית של הנתונים שנאספו מתומללת לפורמט טקסט.
דיבור לטקסט מבולבל לעתים קרובות עם זיהוי קול, השונה לחלוטין משיטה זו. בזיהוי קול, ההתמקדות היא בזיהוי דפוסי הקול של אנשים, ואילו בשיטה זו המערכת מנסה לזהות את המילים הנאמרות.
שמות נפוצים של דיבור לטקסט
טכנולוגיית זיהוי דיבור מתקדמת זו היא גם פופולרית ומכונה בשמות:
- זיהוי דיבור אוטומטי (ASR)
- זיהוי דיבור
- זיהוי דיבור במחשב
- תמלול אודיו
- קריאת מסך
הבנת פעולתו של זיהוי דיבור אוטומטי
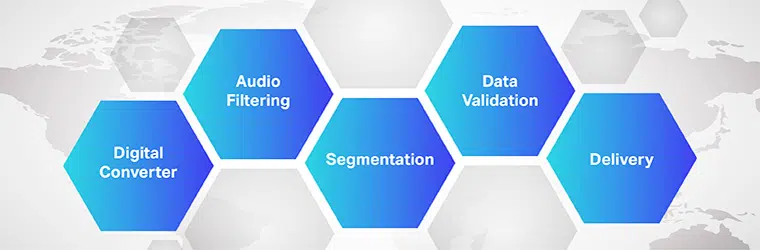
העבודה של תוכנת תרגום אודיו לטקסט מורכבת וכרוכה ביישום של מספר שלבים. כידוע, דיבור לטקסט היא תוכנה בלעדית המיועדת להמיר קבצי אודיו לפורמט טקסט הניתן לעריכה; הוא עושה זאת על ידי מינוף זיהוי קולי.
התַהֲלִיך
- בתחילה, באמצעות ממיר אנלוגי לדיגיטלי, תוכנית מחשב מיישמת אלגוריתמים לשוניים על הנתונים המסופקים כדי להבחין בין רעידות לאותות שמיעתיים.
- לאחר מכן, הצלילים הרלוונטיים מסוננים על ידי מדידת גלי הקול.
- יתר על כן, הצלילים מחולקים/מפולחים למאות או אלפיות של שניות ומותאמים לפונמות (יחידה ניתנת למדידה של צליל להבדיל בין מילה אחת לאחרת).
- הפונמות עוברות בהמשך מודל מתמטי כדי להשוות את הנתונים הקיימים עם מילים, משפטים וביטויים ידועים.
- הפלט הוא בקובץ טקסט או קובץ שמע מבוסס מחשב.
[קרא גם: סקירה מקיפה של זיהוי דיבור אוטומטי]

מהם השימושים בדיבור לטקסט?
ישנם מספר שימושים בתוכנות לזיהוי דיבור אוטומטי, כגון
- חיפוש תוכן: רובנו עברנו מהקלדת אותיות בטלפון ללחיצה על כפתור כדי שהתוכנה תזהה את הקול שלנו ותספק את התוצאות הרצויות.
- שירות לקוחות: צ'אטבוטים ועוזרי בינה מלאכותית שיכולים להדריך את הלקוחות בכמה שלבים ראשוניים של התהליך הפכו נפוצים.
- כתוביות סגורות בזמן אמת: עם גישה גלובלית מוגברת לתוכן, כתוביות סגורות בזמן אמת הפכו לשוק בולט ומשמעותי, שדוחף את ASR קדימה לשימוש שלה.
- תיעוד אלקטרוני: מספר מחלקות אדמיניסטרציה החלו להשתמש ב-ASR כדי למלא את מטרות התיעוד, תוך שמירה על מהירות ויעילות טובים יותר.
מהם האתגרים המרכזיים לזיהוי דיבור?
הערת אודיו עדיין לא הגיעה לשיא התפתחותו. יש עדיין אתגרים רבים שהמהנדסים מנסים להתמודד איתם כדי להפוך את המערכת ליעילה, כגון
- השגת שליטה על מבטאים ודיאלקטים.
- הבנת ההקשר של המשפטים המדוברים.
- הפרדה של רעשי רקע להגברת איכות הקלט.
- העברת הקוד לשפות שונות לעיבוד יעיל.
- ניתוח הרמזים הוויזואליים המשמשים בדיבור במקרה של קבצי וידאו.
תמלול אודיו ופיתוח בינה מלאכותית של דיבור לטקסט
האתגר הגדול ביותר עם תוכנת זיהוי דיבור אוטומטי הוא יצירת הפלט שלה במדויק ב-100%. מכיוון שהנתונים הגולמיים הם דינמיים ולא ניתן ליישם אלגוריתם בודד, הנתונים מסומנים כדי לאמן את ה-AI להבין אותם בהקשר הנכון.
כדי לבצע תהליך זה, יש ליישם משימות ספציפיות, כגון:
 זיהוי ישות בשם (NER): נר הוא תהליך של זיהוי ופילוח של ישויות שונות בשמות לקטגוריות ספציפיות.
זיהוי ישות בשם (NER): נר הוא תהליך של זיהוי ופילוח של ישויות שונות בשמות לקטגוריות ספציפיות.- ניתוח סנטימנטים ונושאים: התוכנה המשתמשת במספר אלגוריתמים מבצעת את ניתוח הסנטימנט של הנתונים שסופקו כדי לספק תוצאות ללא שגיאות.
 זיהוי ישות בשם (NER):
זיהוי ישות בשם (NER): - ניתוח כוונות ושיחה: זיהוי כוונות נועד לאמן את ה-AI לזהות את כוונת הדובר. הוא משמש בעיקר ליצירת צ'אטבוטים המופעלים על ידי בינה מלאכותית.
סיכום
טכנולוגיית דיבור לטקסט נמצאת בשלב מצוין כרגע. עם יותר מכשירים דיגיטליים המשלבים עוזרי חיפוש ושליטה קוליים באפליקציות שלהם, הביקוש לתמלול אודיו צפוי לעלות. אם אתה מעוניין להוסיף את התכונה המרשימה הזו לאפליקציה שלך, צור קשר עם מומחי איסוף נתוני הדיבור של שייפ כדי לדעת את הפרטים המלאים.


