
בינה מלאכותית, ביג דאטה ולמידת מכונה ממשיכות להשפיע על קובעי מדיניות, עסקים, מדע, בתי מדיה ומגוון תעשיות ברחבי העולם. דיווחים מצביעים על כך ששיעור האימוץ העולמי של AI נמצא כעת 35% ב2022 - עלייה עצומה של 4% משנת 2021. על פי הדיווחים, 42% נוספים מהחברות בודקות את היתרונות הרבים של AI עבור העסק שלהן.
מניע את יוזמות הבינה המלאכותית הרבות ו למידת מכונה פתרונות הם נתונים. AI יכול להיות טוב רק כמו הנתונים שמזינים את האלגוריתם. נתונים באיכות נמוכה עלולים לגרום לתוצאות באיכות נמוכה ותחזיות לא מדויקות.
למרות שהייתה תשומת לב רבה בפיתוח פתרונות ML ו-AI, חסרה המודעות למה שמתאים כמערך נתונים איכותי. במאמר זה, אנו מנווטים בציר הזמן של נתוני אימון AI איכותיים ולזהות את העתיד של AI באמצעות הבנה של איסוף נתונים והדרכה.
הגדרה של נתוני אימון בינה מלאכותית
בעת בניית פתרון ML, יש חשיבות לכמות ואיכות מערך ההדרכה. מערכת ה-ML לא רק דורשת כמויות גדולות של נתוני אימון דינמיים, לא מוטים ובעלי ערך, אלא היא גם צריכה הרבה מהם.
אבל מהם נתוני אימון בינה מלאכותית?
נתוני אימון בינה מלאכותית הם אוסף של נתונים מסומנים המשמשים לאימון אלגוריתם ML לביצוע תחזיות מדויקות. מערכת ה-ML מנסה לזהות ולזהות דפוסים, להבין קשרים בין פרמטרים, לקבל החלטות נחוצות ולהעריך על סמך נתוני האימון.
קח את הדוגמה של מכוניות בנהיגה עצמית, למשל. מערך ההדרכה למודל ML לנהיגה עצמית צריך לכלול תמונות וסרטוני וידאו מתויגים של מכוניות, הולכי רגל, שלטי רחוב וכלי רכב אחרים.
בקיצור, כדי לשפר את האיכות של אלגוריתם ML, אתה צריך כמויות גדולות של נתוני אימון מובנים היטב, מוערים ומתויגים.
החשיבות של נתוני אימון איכותיים וההתפתחות שלהם
נתוני אימון באיכות גבוהה הם הקלט העיקרי בפיתוח אפליקציות AI ו-ML. הנתונים נאספים ממקורות שונים ומוצגים בצורה לא מאורגנת שאינה מתאימה למטרות למידת מכונה. נתוני אימון איכותיים - מתויגים, מבוארים ומתויגים - הם תמיד בפורמט מאורגן - אידיאלי לאימון ML.
נתוני אימון איכותיים מקלים על מערכת ה-ML לזהות אובייקטים ולסווג אותם לפי תכונות שנקבעו מראש. מערך הנתונים עלול להניב תוצאות מודל גרועות אם הסיווג אינו מדויק.
הימים הראשונים של נתוני אימון בינה מלאכותית
למרות ש-AI שולט בעולם העסקים והמחקר הנוכחי, הימים הראשונים לפני ML שלטה בינה מלאכותית היה שונה לגמרי.
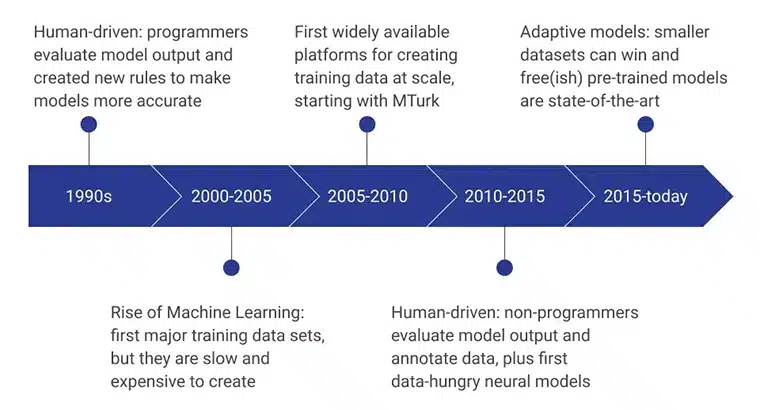
השלבים הראשוניים של נתוני אימון בינה מלאכותית הופעלו על ידי מתכנתים אנושיים שהעריכו את תפוקת המודל על ידי תכנון עקבי של כללים חדשים שהפכו את המודל ליעיל יותר. בתקופת 2000 - 2005, נוצר מערך הנתונים הגדול הראשון, וזה היה תהליך איטי ביותר, תלוי במשאבים ויקר. זה הוביל לבניית מערכי נתונים להדרכה בקנה מידה, ו-MTurk של אמזון מילא תפקיד משמעותי בשינוי התפיסות של אנשים לגבי איסוף נתונים. במקביל, התיוג והביאור אנושיים המריאו גם הם.
השנים הבאות התמקדו בלא מתכנתים ליצור ולהעריך את מודל הנתונים. נכון לעכשיו, ההתמקדות היא במודלים שהוכשרו מראש שפותחו תוך שימוש בשיטות מתקדמות לאיסוף נתוני אימון.
כמות על פני איכות
כאשר העריכו את תקינותם של מערכי אימון בינה מלאכותית בעבר, מדעני נתונים התמקדו ב כמות נתוני אימון בינה מלאכותית על איכות.
לדוגמה, הייתה טעות נפוצה שמאגרי מידע גדולים מספקים תוצאות מדויקות. נפח הנתונים העצום נחשב כאינדיקטור טוב לערך הנתונים. הכמות היא רק אחד הגורמים העיקריים הקובעים את הערך של מערך הנתונים - התפקיד של איכות הנתונים הוכר.
המודעות לכך איכות נתונים תלוי בשלמות הנתונים, עלייה מהימנות, תקפות, זמינות ועמידה בזמנים. והכי חשוב, התאמת הנתונים לפרויקט קבעה את איכות הנתונים שנאספו.
מגבלות של מערכות AI מוקדמות עקב נתוני אימון לקויים
נתוני אימון גרועים, יחד עם היעדר מערכות מחשוב מתקדמות, היו אחת הסיבות לכמה הבטחות שלא מומשו של מערכות AI מוקדמות.
בשל היעדר נתוני אימון איכותיים, פתרונות ML לא יכלו לזהות במדויק דפוסים חזותיים המעכבים את התפתחות המחקר העצבי. למרות שחוקרים רבים זיהו את ההבטחה לזיהוי שפה מדוברת, מחקר או פיתוח של כלי זיהוי דיבור לא יכלו להתממש הודות להעדר מערכי נתונים של דיבור. מכשול מרכזי נוסף לפיתוח כלי AI מתקדמים היה היעדר יכולות חישוב ואחסון של המחשבים.
המעבר לנתוני אימון איכותיים
חל שינוי ניכר במודעות לכך שהאיכות של מערך הנתונים חשובה. כדי שמערכת ה-ML תחקה במדויק אינטליגנציה אנושית ויכולות קבלת החלטות, עליה לשגשג על נתוני אימון בנפח גבוה ואיכותי.
חשבו על נתוני ה-ML שלכם כעל סקר - ככל שהגודל גדול יותר מדגם נתונים גודל, כך התחזית טובה יותר. אם נתוני המדגם אינם כוללים את כל המשתנים, ייתכן שהם לא יזהו דפוסים או יביאו למסקנות לא מדויקות.
התקדמות בטכנולוגיית AI והצורך בנתוני אימון טובים יותר
 ההתקדמות בטכנולוגיית AI מגדילה את הצורך בנתוני אימון איכותיים.
ההתקדמות בטכנולוגיית AI מגדילה את הצורך בנתוני אימון איכותיים.ההבנה שנתוני אימון טובים יותר מגדילים את הסיכוי למודלים אמינים של ML הולידה מתודולוגיות טובות יותר של איסוף נתונים, הערות ותיוג. האיכות והרלוונטיות של הנתונים השפיעו ישירות על איכות מודל הבינה המלאכותית.
 ההתקדמות בטכנולוגיית AI מגדילה את הצורך בנתוני אימון איכותיים.
ההתקדמות בטכנולוגיית AI מגדילה את הצורך בנתוני אימון איכותיים.התמקדות מוגברת באיכות ודיוק הנתונים
כדי שמודל ה-ML יתחיל לספק תוצאות מדויקות, הוא ניזון ממערכי נתונים איכותיים שעוברים שלבי חידוד נתונים איטרטיביים.
לדוגמה, ייתכן שאדם יוכל לזהות גזע ספציפי של כלב תוך מספר ימים לאחר היכרות עם הגזע - באמצעות תמונות, סרטונים או באופן אישי. בני אדם שואבים מניסיונם וממידע קשור כדי לזכור ולמשוך את הידע הזה בעת הצורך. עם זאת, זה לא עובד באותה קלות עבור מכונה. יש להזין את המכונה בתמונות עם הערות ותיוג ברור - מאות או אלפים - של הגזע המסוים הזה ומגזעים אחרים כדי שהיא תיצור את החיבור.
מודל AI מנבא את התוצאה על ידי התאמה בין המידע המאומן לבין המידע המוצג ב- עולם אמיתי. האלגוריתם הופך חסר תועלת אם נתוני האימון אינם כוללים מידע רלוונטי.
חשיבות נתוני הכשרה מגוונים ומייצגים
הגיוון בנתונים מוגבר גם מגביר את היכולת, מפחית את ההטיה ומגביר ייצוג שוויוני של כל התרחישים. אם מודל הבינה המלאכותית מאומן באמצעות מערך נתונים הומוגני, אתה יכול להיות בטוח שהאפליקציה החדשה תעבוד רק למטרה מסוימת ותשרת אוכלוסייה מסוימת.מערך נתונים עלול להיות מוטה כלפי אוכלוסייה מסוימת, גזע, מגדר, בחירה ודעות אינטלקטואליות, מה שעלול להוביל למודל לא מדויק.
חשוב להבטיח שכל זרימת תהליך איסוף הנתונים, לרבות בחירת מאגר הנושאים, האצירה, ההערות והתיוג, תהיה מגוונת במידה מספקת, מאוזנת ומייצגת את האוכלוסייה.
 הגיוון בנתונים מוגבר גם מגביר את היכולת, מפחית את ההטיה ומגביר ייצוג שוויוני של כל התרחישים. אם מודל הבינה המלאכותית מאומן באמצעות מערך נתונים הומוגני, אתה יכול להיות בטוח שהאפליקציה החדשה תעבוד רק למטרה מסוימת ותשרת אוכלוסייה מסוימת.
הגיוון בנתונים מוגבר גם מגביר את היכולת, מפחית את ההטיה ומגביר ייצוג שוויוני של כל התרחישים. אם מודל הבינה המלאכותית מאומן באמצעות מערך נתונים הומוגני, אתה יכול להיות בטוח שהאפליקציה החדשה תעבוד רק למטרה מסוימת ותשרת אוכלוסייה מסוימת.העתיד של נתוני אימון בינה מלאכותית
ההצלחה העתידית של מודלים של AI תלויה באיכות ובכמות נתוני האימון המשמשים לאימון אלגוריתמי ה-ML. חשוב להכיר בכך שהקשר הזה בין איכות הנתונים לכמות הוא ספציפי למשימה ואין לו תשובה חד משמעית.
בסופו של דבר, ההתאמה של מערך נתוני אימון מוגדר על ידי יכולתו לבצע ביצועים טובים באופן מהימן למטרה שהוא בנוי.
התקדמות בטכניקות איסוף נתונים והערות
מכיוון ש-ML רגיש לנתונים המוזנים, חיוני לייעל את מדיניות איסוף הנתונים וההערות. שגיאות באיסוף נתונים, איסוף, מצג שווא, מדידות לא שלמות, תוכן לא מדויק, שכפול נתונים ומדידות שגויות תורמים לאיכות נתונים לא מספקת.
איסוף נתונים אוטומטי באמצעות כריית נתונים, גירוד אינטרנט והפקת נתונים סולל את הדרך ליצירת נתונים מהיר יותר. בנוסף, מערכי נתונים ארוזים מראש פועלים כטכניקת איסוף נתונים לתיקון מהיר.
מיקור המונים הוא שיטה פורצת דרך נוספת לאיסוף נתונים. אמנם לא ניתן להבטיח את אמיתות הנתונים, אך זהו כלי מצוין לאיסוף תדמית ציבורית. לבסוף, מתמחה איסוף הנתונים מומחים מספקים גם נתונים שמקורם במטרות ספציפיות.
דגש מוגבר על שיקולים אתיים בנתוני הכשרה
עם ההתקדמות המהירה ב-AI, צצו כמה סוגיות אתיות, במיוחד באיסוף נתונים. כמה שיקולים אתיים באיסוף נתוני הכשרה כוללים הסכמה מדעת, שקיפות, הטיה ופרטיות נתונים.מאחר שהנתונים כוללים כעת הכל, החל מתמונות פנים, טביעות אצבע, הקלטות קול ונתונים ביומטריים קריטיים אחרים, זה הופך להיות חשוב ביותר להבטיח הקפדה על נהלים משפטיים ואתיים כדי למנוע תביעות משפטיות יקרות ופגיעה במוניטין.
הפוטנציאל לנתוני הכשרה איכותיים ומגוונים אף יותר בעתיד
יש פוטנציאל עצום עבור נתוני הדרכה איכותיים ומגוונים בעתיד. הודות למודעות לאיכות הנתונים ולזמינותם של ספקי נתונים הנותנים מענה לדרישות האיכות של פתרונות AI.
ספקי נתונים בהווה מיומנים בשימוש בטכנולוגיות פורצות דרך למקור אתי וחוקי בכמויות אדירות של מערכי נתונים מגוונים. יש להם גם צוותים פנימיים לתיוג, להעיר ולהציג את הנתונים המותאמים אישית לפרויקטים שונים של ML.
 עם ההתקדמות המהירה ב-AI, צצו כמה סוגיות אתיות, במיוחד באיסוף נתונים. כמה שיקולים אתיים באיסוף נתוני הכשרה כוללים הסכמה מדעת, שקיפות, הטיה ופרטיות נתונים.
עם ההתקדמות המהירה ב-AI, צצו כמה סוגיות אתיות, במיוחד באיסוף נתונים. כמה שיקולים אתיים באיסוף נתוני הכשרה כוללים הסכמה מדעת, שקיפות, הטיה ופרטיות נתונים.סיכום
חשוב לשתף פעולה עם ספקים אמינים עם הבנה אקוטית של נתונים ואיכות לפתח דגמי AI מתקדמים. Shaip היא חברת ההערות המובילה המיומנת במתן פתרונות נתונים מותאמים אישית העונים על הצרכים והיעדים של פרויקט הבינה המלאכותית שלך. שותפו איתנו וחקרו את הכישורים, המחויבות ושיתוף הפעולה שאנו מביאים לשולחן.


