
מבוא
מדריך זה יעזור מאוד לאותם קונים ומקבלי החלטות שמתחילים להפנות את מחשבותיהם לעבר האגוזים והברגים של מקור נתונים והטמעת נתונים הן עבור רשתות עצביות והן מסוגים אחרים של פעולות AI ו- ML.

מאמר זה מוקדש לחלוטין לשפוך אור על התהליך, מדוע הוא בלתי נמנע, קריטי
גורמים שחברות צריכות לקחת בחשבון כאשר ניגשים לכלי ביאור נתונים ועוד. לכן, אם אתה בעל עסק, התכונן להארה מכיוון שמדריך זה ילווה אותך בכל מה שאתה צריך לדעת על ביאורי נתונים.
בואו נתחיל.
לאלו מכם שדפדפו במאמר, הנה כמה מהלכים מהירים שתמצאו במדריך:
- הבן מהי הערת נתונים
- דע את הסוגים השונים של תהליכי הערת נתונים
- דע את היתרונות של יישום תהליך ביאור הנתונים
- קבל בהירות אם עליך ללכת לסימון נתונים פנימי או להוציא אותם למיקור חוץ
- גם תובנות לגבי בחירת הערת הנתונים הנכונה
מהי למידת מכונה?
 דיברנו על איך ביאור נתונים או תיוג נתונים תומך בלמידת מכונה ושהוא מורכב מתיוג או זיהוי רכיבים. אך באשר ללמידה עמוקה ולמידת מכונה עצמה: הנחת היסוד של למידת מכונה היא שמערכות ותוכנות מחשב יכולות לשפר את תפוקתן בדרכים הדומות לתהליכים קוגניטיביים אנושיים, ללא עזרה או התערבות אנושית ישירה, כדי לתת לנו תובנות. במילים אחרות, הם הופכים למכונות למידה עצמית, בדומה לאדם, הופכות טובות יותר בעבודתן עם יותר תרגול. "תרגול" זה מושג מניתוח ופירוש נתוני אימון נוספים (וטובים יותר).
דיברנו על איך ביאור נתונים או תיוג נתונים תומך בלמידת מכונה ושהוא מורכב מתיוג או זיהוי רכיבים. אך באשר ללמידה עמוקה ולמידת מכונה עצמה: הנחת היסוד של למידת מכונה היא שמערכות ותוכנות מחשב יכולות לשפר את תפוקתן בדרכים הדומות לתהליכים קוגניטיביים אנושיים, ללא עזרה או התערבות אנושית ישירה, כדי לתת לנו תובנות. במילים אחרות, הם הופכים למכונות למידה עצמית, בדומה לאדם, הופכות טובות יותר בעבודתן עם יותר תרגול. "תרגול" זה מושג מניתוח ופירוש נתוני אימון נוספים (וטובים יותר).
מהי הערת נתונים?
הערת נתונים היא תהליך של ייחוס, תיוג או תיוג נתונים כדי לעזור לאלגוריתמים של למידת מכונה להבין ולסווג את המידע שהם מעבדים. תהליך זה חיוני לאימון מודלים של AI, המאפשר להם להבין במדויק סוגי נתונים שונים, כגון תמונות, קבצי אודיו, קטעי וידאו או טקסט.
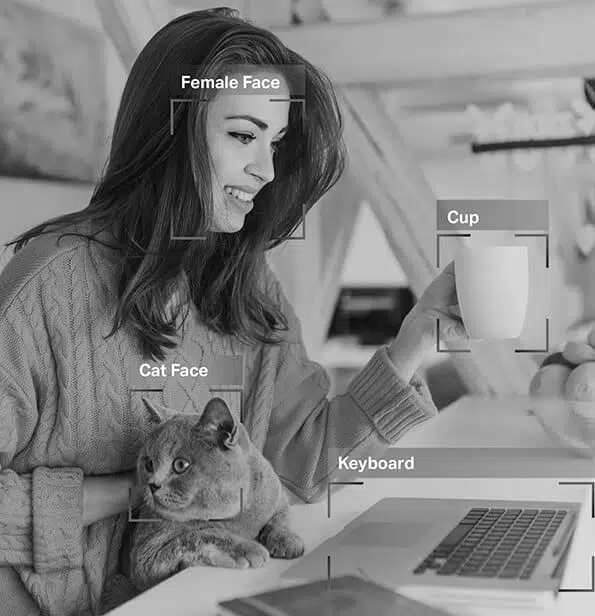
דמיינו לעצמכם מכונית בנהיגה עצמית המסתמכת על נתונים מראייה ממוחשבת, עיבוד שפה טבעית (NLP) וחיישנים כדי לקבל החלטות נהיגה מדויקות. כדי לעזור למודל הבינה המלאכותית של המכונית להבדיל בין מכשולים כמו כלי רכב אחרים, הולכי רגל, בעלי חיים או חסימות כבישים, הנתונים שהיא מקבלת חייבים להיות מתויגים או להערות.
בלמידה מפוקחת, הערת נתונים היא קריטית במיוחד, שכן ככל שהנתונים מתויגים יותר למודל, כך הוא לומד מהר יותר לתפקד באופן אוטונומי. נתונים מוערים מאפשרים לפרוס מודלים של AI ביישומים שונים כמו צ'טבוטים, זיהוי דיבור ואוטומציה, וכתוצאה מכך ביצועים מיטביים ותוצאות אמינות.
מהו כלי לסימון/ביאור נתונים?
 במילים פשוטות, זוהי פלטפורמה או פורטל המאפשר למומחים ומומחים להערות, לתייג או לתייג מערכי נתונים מכל הסוגים. זהו גשר או אמצעי בין נתונים גולמיים לבין התוצאות שבסופו של דבר המודולים של למידת מכונה היו מסתלקים.
במילים פשוטות, זוהי פלטפורמה או פורטל המאפשר למומחים ומומחים להערות, לתייג או לתייג מערכי נתונים מכל הסוגים. זהו גשר או אמצעי בין נתונים גולמיים לבין התוצאות שבסופו של דבר המודולים של למידת מכונה היו מסתלקים.
כלי לסימון נתונים הוא פתרון מקומי או מבוסס ענן המביא נתונים על אימון איכותי עבור מודלים של למידת מכונה. למרות שחברות רבות מסתמכות על ספק חיצוני שיבצע הערות מורכבות, לארגונים מסוימים עדיין יש כלים משלהם שנבנים בהתאמה אישית או שמבוססים על כלי תוכנה חופשית או פתוחה הזמינים בשוק. כלים כאלה נועדו בדרך כלל להתמודד עם סוגי נתונים ספציפיים, כלומר, תמונה, וידאו, טקסט, אודיו וכו '. הכלים מציעים תכונות או אפשרויות כמו תיבות תחום או מצולעים למערבי נתונים לתווית תמונות. הם יכולים פשוט לבחור את האפשרות ולבצע את המשימות הספציפיות שלהם.
ביאור תמונה

ממערכי הנתונים עליהם קיבלו הכשרה הם יכולים לבדל באופן מיידי ומדויק את העיניים שלך מהאף ואת הגבה שלך מהריסים שלך. לכן המסננים שאתה מיישם מתאימים בצורה מושלמת ללא קשר לצורת הפנים שלך, עד כמה אתה קרוב למצלמה שלך ועוד.
אז, כפי שאתה יודע עכשיו, ביאור תמונה חיוני במודולים הכוללים זיהוי פנים, ראייה ממוחשבת, ראייה רובוטית ועוד. כאשר מומחי AI מאמנים מודלים כאלה, הם מוסיפים כיתובים, מזהים ומילות מפתח כתכונות לתמונות שלהם. האלגוריתמים מזהים ומבינים מפרמטרים אלה ולומדים באופן אוטונומי.
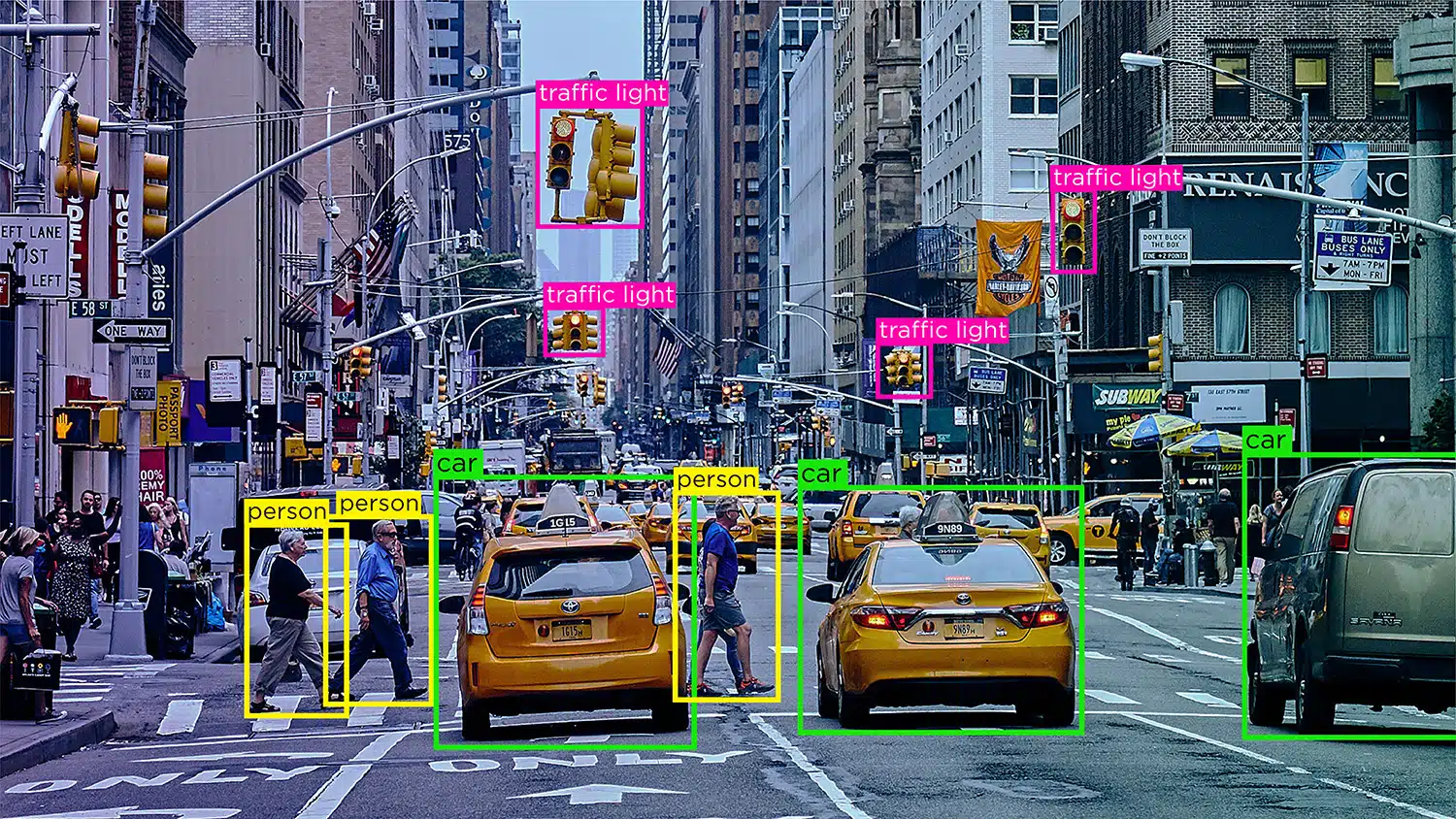
סיווג תמונה - סיווג תמונות כולל הקצאת קטגוריות או תוויות מוגדרות מראש לתמונות על סמך התוכן שלהן. סוג זה של הערות משמש לאימון מודלים של AI לזהות ולסווג תמונות באופן אוטומטי.
זיהוי/זיהוי אובייקטים - זיהוי אובייקטים, או זיהוי אובייקטים, הוא תהליך של זיהוי ותיוג אובייקטים ספציפיים בתוך תמונה. הערות מסוג זה משמשות לאימון מודלים של בינה מלאכותית לאתר ולזהות אובייקטים בתמונות או בסרטונים מהעולם האמיתי.
פילוח - פילוח תמונה כולל חלוקת תמונה למספר מקטעים או אזורים, כל אחד מתאים לאובייקט או אזור עניין ספציפי. הערות מסוג זה משמשות לאימון מודלים של AI לנתח תמונות ברמת פיקסלים, מה שמאפשר זיהוי אובייקט מדויק יותר והבנת סצנה.
ביאור שמע
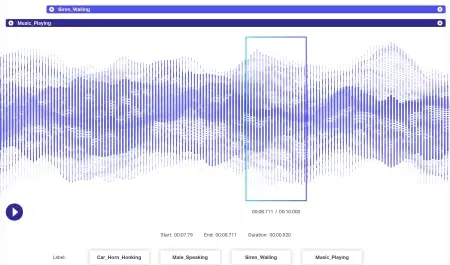
לנתוני שמע יש דינמיקה רבה יותר מאשר נתוני תמונה. כמה גורמים קשורים לקובץ שמע כולל אך בהחלט לא מוגבל לשפה, דמוגרפיה של דוברים, ניבים, מצב רוח, כוונה, רגש, התנהגות. כדי שאלגוריתמים יהיו יעילים בעיבוד, יש לזהות ולתייג את כל הפרמטרים הללו על ידי טכניקות כגון חותמת זמן, תיוג שמע ועוד. מלבד רמזים מילוליים בלבד, ניתן להעלות הערות על מקרים לא מילוליים כמו שתיקה, נשימות, ואפילו רעשי רקע, כך שמערכות יבינו באופן מקיף.
ביאור וידאו

בעוד שתמונה דוממת, סרטון הוא אוסף תמונות שיוצר אפקט של עצמים הנמצאים בתנועה. כעת, כל תמונה באוסף זה נקראת מסגרת. בכל הנוגע להערת וידיאו, התהליך כולל הוספה של מקשי מקשים, מצולעים או תיבות תוחמות כדי להערות על אובייקטים שונים בשדה בכל פריים.
כאשר מסגרות אלה מחוברות יחדיו, ניתן ללמוד את התנועה, ההתנהגות, הדפוסים ועוד על ידי דגמי הבינה המלאכותית בפעולה. זה רק דרך ביאור וידאו שאפשר ליישם מושגים כמו לוקליזציה, טשטוש תנועה ומעקב אחר אובייקטים במערכות.
ביאור טקסט

כיום רוב העסקים מסתמכים על נתונים מבוססי טקסט לקבלת תובנה ומידע ייחודיים. עכשיו, טקסט יכול להיות כל דבר החל משוב לקוחות על אפליקציה ועד אזכור ברשתות החברתיות. ובניגוד לתמונות וסרטונים שבעיקר משדרים כוונות שהן פשוטות, הטקסט מגיע עם הרבה סמנטיקה.
כבני אדם, אנו מכוונים להבין את ההקשר של ביטוי, את המשמעות של כל מילה, משפט או ביטוי, לקשר אותם למצב מסוים או לשיחה ואז להבין את המשמעות ההוליסטית מאחורי הצהרה. לעומת זאת, מכונות אינן יכולות לעשות זאת ברמות מדויקות. מושגים כמו סרקזם, הומור ואלמנטים מופשטים אחרים אינם ידועים להם ולכן תיוג נתוני הטקסט הופך להיות קשה יותר. זו הסיבה להערת טקסט יש כמה שלבים מעודנים יותר כמו הבאים:
ביאור סמנטי - אובייקטים, מוצרים ושירותים הופכים לרלוונטיים יותר על ידי פרמטרים תיוג וזיהוי מתאימים של מילות מפתח. צ'ט-בוטים נועדו גם לחקות שיחות אנושיות בדרך זו.
ביאור כוונה - כוונת המשתמש והשפה בה משתמשים הם מתויגים להבנת מכונות. בעזרת זה, מודלים יכולים להבדיל בין בקשה לפקודה, או המלצה מהזמנה, וכן הלאה.
הערת סנטימנט - הערת סנטימנט כוללת תיוג נתונים טקסטואליים עם הסנטימנט שהם מעבירים, כגון חיובי, שלילי או ניטרלי. סוג זה של הערות משמש בדרך כלל בניתוח סנטימנטים, שבו מודלים של AI מאומנים להבין ולהעריך את הרגשות המובעים בטקסט.

ביאור ישויות - שם מתויגים משפטים לא מובנים כדי להפוך אותם למשמעותיים יותר ולהביא אותם לפורמט שניתן להבין על ידי מכונות. כדי לגרום לזה לקרות, מעורבים שני היבטים - הכרה בישויות בשם ו קישור ישויות. זיהוי ישויות בשם הוא כאשר שמות של מקומות, אנשים, אירועים, ארגונים ועוד מתויגים ומזוהים וקישור ישויות הוא כאשר תגים אלה מקושרים למשפטים, ביטויים, עובדות או דעות הבאים בעקבותיהם. באופן קולקטיבי, שני התהליכים הללו מבססים את הקשר בין הטקסטים הקשורים לאמירה סביבו.
קטגוריות טקסט - ניתן לתייג ולסווג משפטים או פסקאות על סמך נושאים, מגמות, נושאים, דעות, קטגוריות (ספורט, בידור וכדומה) ופרמטרים אחרים.
שלבים מרכזיים בתהליך תיוג נתונים והערת נתונים
תהליך הערת הנתונים כולל סדרה של שלבים מוגדרים היטב כדי להבטיח תיוג נתונים איכותי ומדויק עבור יישומי למידת מכונה. שלבים אלה מכסים כל היבט של התהליך, מאיסוף נתונים ועד לייצוא הנתונים המוערים לשימוש נוסף.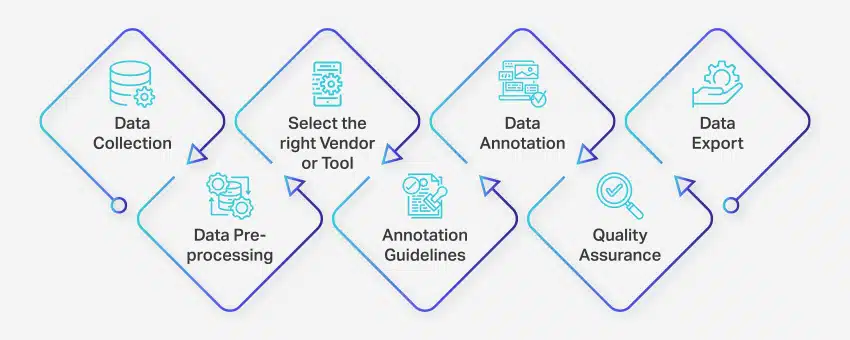
כך מתרחש הערת נתונים:
- איסוף נתונים: השלב הראשון בתהליך הערת הנתונים הוא לאסוף את כל הנתונים הרלוונטיים, כגון תמונות, סרטונים, הקלטות אודיו או נתוני טקסט, במיקום מרכזי.
- עיבוד מוקדם של נתונים: תקן ושפר את הנתונים שנאספו על ידי ביטול הטיית תמונות, עיצוב טקסט או תמלול תוכן וידאו. עיבוד מוקדם מבטיח שהנתונים מוכנים להערה.
- בחר את הספק או הכלי הנכון: בחר בכלי או ספק מתאים להערות נתונים בהתאם לדרישות הפרויקט שלך. האפשרויות כוללות פלטפורמות כמו Nanonets עבור הערת נתונים, V7 עבור הערת תמונה, Appen עבור הערת וידאו, ו Nanonets עבור הערת מסמך.
- הנחיות הערות: קבע קווים מנחים ברורים למפרטים או לכלי הערות כדי להבטיח עקביות ודיוק לאורך כל התהליך.
- ביאור: תייגו את הנתונים ותייגו אותם באמצעות כותבים אנושיים או תוכנת הערות נתונים, בהתאם להנחיות שנקבעו.
- אבטחת איכות (QA): סקור את הנתונים המוערים כדי להבטיח דיוק ועקביות. השתמש במספר הערות עיוורות, במידת הצורך, כדי לאמת את איכות התוצאות.
- ייצוא נתונים: לאחר השלמת הערת הנתונים, ייצא את הנתונים בפורמט הנדרש. פלטפורמות כמו Nanonets מאפשרות ייצוא נתונים חלק ליישומי תוכנה עסקיים שונים.
כל תהליך הערת הנתונים יכול לנוע בין מספר ימים למספר שבועות, בהתאם לגודל הפרויקט, המורכבות והמשאבים הזמינים של הפרויקט.
תכונות לכלי הערת נתונים וסימון נתונים
כלים לביאור נתונים הם גורמים מכריעים שיכולים לגרום לפרויקט ה- AI שלך או לשבור אותו. בכל הנוגע לתפוקות ותוצאות מדויקות, אין חשיבות לאיכות מערכי הנתונים בלבד. למעשה, כלי ביאורי הנתונים שבהם אתה משתמש כדי לאמן את מודולי ה- AI שלך משפיעים מאוד על התפוקות שלך.
לכן חיוני לבחור ולהשתמש בכלי תיוג הנתונים המתפקד והמתאים ביותר העונה על צרכי העסק או הפרויקט שלך. אבל מהו כלי ביאור נתונים מלכתחילה? איזו מטרה היא משרתת? האם יש סוגים? ובכן, בואו לגלות.
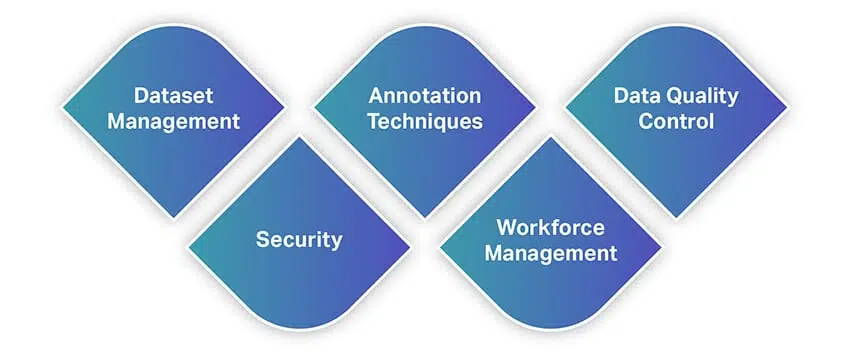
בדומה לכלים אחרים, כלי ביאור הנתונים מציעים מגוון רחב של תכונות ויכולות. כדי לתת לך מושג מהיר על התכונות, הנה רשימה של כמה מהתכונות הבסיסיות ביותר שעליך לחפש בעת בחירת כלי לביאור נתונים.
ניהול מערכי נתונים
כלי ביאור הנתונים שאתה מתכוון להשתמש בו חייב לתמוך במערכות הנתונים שיש לך ביד ולאפשר לך לייבא אותם לתוכנה לצורך תיוג. אם כן, ניהול מערכי הנתונים שלך הוא ההצעה העיקרית של כלי התכונות. פתרונות עכשוויים מציעים תכונות המאפשרות לך לייבא כמויות גבוהות של נתונים בצורה חלקה, ובמקביל לאפשר לך לארגן את מערכי הנתונים שלך באמצעות פעולות כמו מיון, סינון, שיבוט, מיזוג ועוד.
לאחר סיום הקלט של מערכי הנתונים שלך, הבא הוא ייצואם כקבצים שמיש. הכלי שבו אתה משתמש אמור לאפשר לך לשמור את מערכי הנתונים שלך בפורמט שאתה מציין כדי שתוכל להאכיל אותם במודלי ה- ML שלך.
טכניקות ביאורים
לשם כך בנוי או מיועד כלי ביאור נתונים. כלי מוצק צריך להציע לך מגוון של טכניקות ביאור למערכי נתונים מכל הסוגים. זאת, אלא אם כן אתה מפתח פתרון מותאם אישית לצרכיך. הכלי שלך אמור לאפשר לך להוסיף הערות לסרטונים או תמונות מחזון מחשב, אודיו או טקסט ממסמכי NLP ותעודות ועוד. אם לחדד זאת עוד יותר, צריכות להיות אפשרויות להשתמש בקופסאות גבול, פילוח סמנטי, קוביות, אינטרפולציה, ניתוח סנטימנט, חלקי דיבור, פתרון התייחסות ועוד.
עבור מי שאינם יזומים, ישנם גם כלי ביאור נתונים המופעלים על ידי AI. אלה מגיעים עם מודולי AI הלומדים באופן אוטונומי מדפוסי העבודה של המביאור ומעירים באופן אוטומטי תמונות או טקסט. כגון
ניתן להשתמש במודולים כדי לספק סיוע מדהים למערינים, לייעל ביאורים ואפילו ליישם בדיקות איכות.
בקרת איכות נתונים
אם כבר מדברים על בדיקות איכות, מספר כלי ביאור נתונים קיימים בחוץ עם מודולים של בדיקת איכות משובצת. אלה מאפשרים למבקרים לשתף פעולה טוב יותר עם חברי הצוות שלהם ולעזור לייעל את תהליכי העבודה. בעזרת תכונה זו, מבארים יכולים לסמן ולעקוב אחר הערות או משוב בזמן אמת, לעקוב אחר זהויות מאחורי אנשים שעושים שינויים בקבצים, לשחזר גרסאות קודמות, לבחור תיוג קונצנזוס ועוד.
אבטחה
מכיוון שאתה עובד עם נתונים, האבטחה צריכה להיות בראש סדר העדיפויות. יתכן שאתה עובד על נתונים חסויים כמו אלה הכוללים פרטים אישיים או קניין רוחני. לכן, הכלי שלך חייב לספק אבטחה אטומה מבחינת המקום שבו הנתונים מאוחסנים וכיצד הם משתפים. עליו לספק כלים המגבילים את הגישה לחברי הצוות, מונעים הורדות לא מורשות ועוד.
מלבד אלה, יש לעמוד בתקני האבטחה והפרוטוקולים ולציית להם.
ניהול כוח אדם
כלי לביאור נתונים הוא גם פלטפורמה לניהול פרויקטים למינהם, שבה ניתן להקצות משימות לחברי צוות, עבודה שיתופית יכולה לקרות, ביקורות אפשריות ועוד. לכן הכלי שלך צריך להתאים לזרימת העבודה ולתהליך שלך לצורך פרודוקטיביות מותאמת.
חוץ מזה, הכלי חייב להיות בעל עקומת למידה מינימלית מכיוון שתהליך ביאור הנתונים כשלעצמו גוזל זמן. זה לא משרת שום מטרה להשקיע יותר מדי זמן בללמוד את הכלי. לכן, זה צריך להיות אינטואיטיבי וחלק עבור כל אחד להתחיל במהירות.
מהם היתרונות של הערת נתונים?
הערת נתונים חיונית לאופטימיזציה של מערכות למידת מכונה ולמתן חוויות משתמש משופרות. הנה כמה יתרונות מרכזיים של הערת נתונים:
- יעילות אימון משופרת: תיוג נתונים מסייע למודלים של למידת מכונה להתאמן טוב יותר, לשפר את היעילות הכוללת ולהפיק תוצאות מדויקות יותר.
- דיוק מוגבר: נתונים עם הערות מדויקות מבטיחים שאלגוריתמים יכולים להסתגל וללמוד ביעילות, וכתוצאה מכך רמות גבוהות יותר של דיוק במשימות עתידיות.
- התערבות אנושית מופחתת: כלים מתקדמים להערת נתונים מפחיתים באופן משמעותי את הצורך בהתערבות ידנית, מייעלים תהליכים והפחתת עלויות נלוות.
לפיכך, הערת נתונים תורמת למערכות למידת מכונה יעילות ומדויקות יותר תוך מזעור העלויות והמאמץ הידני הנדרש באופן מסורתי לאימון מודלים של AI.
לבנות או לא לבנות כלי להערת נתונים
נושא אחד קריטי ועיקרי שעשוי לעלות במהלך פרויקט הערות נתונים או תיוג נתונים הוא הבחירה לבנות או לקנות פונקציונליות לתהליכים אלה. זה עשוי לעלות מספר פעמים בשלבי פרויקט שונים, או קשור למקטעים שונים של התוכנית. בבחירה אם לבנות מערכת באופן פנימי או להסתמך על ספקים, תמיד יש פשרה.

כפי שאתה יכול לומר כעת, הערות נתונים הן תהליך מורכב. יחד עם זאת, זהו גם תהליך סובייקטיבי. כלומר, אין תשובה אחת לשאלה האם עליכם לקנות או לבנות כלי הערת נתונים. צריך לקחת בחשבון הרבה גורמים ואתה צריך לשאול את עצמך כמה שאלות כדי להבין את הדרישות שלך ולהבין אם אתה באמת צריך לקנות או לבנות.
כדי להפוך את זה לפשוט, הנה כמה מהגורמים שכדאי לקחת בחשבון.
המטרה שלך
האלמנט הראשון שעליך להגדיר הוא המטרה עם מושגי הבינה המלאכותית שלך ולמידת מכונה.
- מדוע אתה מיישם אותם בעסק שלך?
- האם הם פותרים בעיה בעולם האמיתי שלקוחותיך מתמודדים?
- האם הם מבצעים תהליך חזיתי או backend כלשהו?
- האם תשתמש ב- AI כדי להציג תכונות חדשות או לייעל את האתר, האפליקציה או המודול הקיימים שלך?
- מה המתחרה שלך עושה בקטע שלך?
- האם יש לך מספיק מקרי שימוש שזקוקים להתערבות AI?
תשובות לאלו ירכזו את מחשבותיך - שעשויות להיות כרגע בכל מקום - למקום אחד ויעניקו לך בהירות רבה יותר.
איסוף / רישוי נתונים של AI
דגמי AI דורשים רק אלמנט אחד לתפקוד - נתונים. עליך לזהות מהיכן תוכל לייצר כמויות אדירות של נתוני אמת קרקעיים. אם העסק שלך מייצר כמויות גדולות של נתונים שצריך לעבד אותם כדי לקבל תובנות מכריעות על עסקים, פעולות, מחקר מתחרים, ניתוח תנודתיות בשוק, מחקר התנהגות לקוחות ועוד, אתה זקוק לכלי ביאור נתונים. עם זאת, עליך לשקול גם את נפח הנתונים שאתה מייצר. כפי שהוזכר קודם לכן, מודל AI יעיל לא פחות מאיכות וכמות הנתונים שהוא מוזן. לכן, ההחלטות שלך תמיד צריכות להיות תלויות בגורם זה.
אם אין לך את הנתונים הנכונים להכשיר את דגמי ה- ML שלך, הספקים יכולים להיות שימושיים למדי ולסייע לך ברישוי נתונים של קבוצת הנתונים הנכונה הדרושה להכשרת דגמי ML. בחלק מהמקרים, חלק מהערך שהספק מביא יכלול גם יכולת טכנית וגם גישה למשאבים שיקדמו את הצלחת הפרויקט.
תַקצִיב
תנאי מהותי נוסף המשפיע ככל הנראה על כל גורם אחד בו אנו דנים כעת. הפתרון לשאלה האם עליכם לבנות או לקנות הערת נתונים הופך להיות קל כשתבינו אם יש לכם מספיק תקציב להוציא.
מורכבות תאימות
 ספקים יכולים להיות מועילים ביותר בכל הנוגע לפרטיות נתונים וטיפול נכון בנתונים רגישים. אחד מסוגי המקרים הללו כולל בית חולים או עסק הקשור בתחום הבריאות המעוניין לנצל את הכוח של למידת מכונה מבלי לסכן את עמידתו ב- HIPAA ובכללי פרטיות נתונים אחרים. גם מחוץ לתחום הרפואי, חוקים כמו ה- GDPR האירופי מחמירים את השליטה בערכות הנתונים, ומחייבים עירנות רבה יותר מצד בעלי העניין בתאגיד.
ספקים יכולים להיות מועילים ביותר בכל הנוגע לפרטיות נתונים וטיפול נכון בנתונים רגישים. אחד מסוגי המקרים הללו כולל בית חולים או עסק הקשור בתחום הבריאות המעוניין לנצל את הכוח של למידת מכונה מבלי לסכן את עמידתו ב- HIPAA ובכללי פרטיות נתונים אחרים. גם מחוץ לתחום הרפואי, חוקים כמו ה- GDPR האירופי מחמירים את השליטה בערכות הנתונים, ומחייבים עירנות רבה יותר מצד בעלי העניין בתאגיד.
כוח אדם
ביאור נתונים דורש כוח אדם מיומן לעבוד עליו ללא קשר לגודל, קנה המידה והתחום של העסק שלך. גם אם אתה מייצר נתונים מינימליים חשובים מדי יום, אתה צריך מומחי נתונים כדי לעבוד על הנתונים שלך לסימון. אז, עכשיו אתה צריך להבין אם יש לך את כוח האדם הנדרש. אם יש לך, האם הם מיומנים בכלים ובטכניקות הנדרשים או שהם זקוקים למיומנויות? אם הם זקוקים למיומנות, האם יש לך תקציב להכשיר אותם מלכתחילה?
יתר על כן, התוכנות הטובות ביותר לביאור נתונים ולתיוג נתונים לוקחות מספר מומחי נושא או תחום ומפלחות אותם לפי דמוגרפיה כמו גיל, מין ותחום התמחות - או לעיתים קרובות מבחינת השפות המקומיות איתן יעבדו. זהו, שוב, שם אנו בשיפ מדברים על השגת האנשים הנכונים למושבים הנכונים ובכך מניעים את התהליכים הנכונים של האדם, אשר יובילו את המאמצים הפרוגרמטיים שלך להצלחה.
הפעלת פרויקטים קטנים וגדולים וסף עלויות
במקרים רבים, תמיכת ספקים יכולה להיות אופציה רבה יותר לפרויקט קטן יותר או לשלבי פרויקטים קטנים יותר. כאשר ניתן לשלוט בעלויות, החברה יכולה להרוויח מיקור חוץ כדי לייעל ביאור נתונים או פרויקטים של תיוג נתונים.
חברות יכולות גם להסתכל על ספים חשובים - שם ספקים רבים קשורים בעלות לכמות הנתונים הנצרכים או לאמות מידה אחרות של משאבים. לדוגמה, נניח שחברה נרשמה עם ספק לביצוע הזנת הנתונים המייגעת הנדרשת להקמת מערכי בדיקה.
ייתכן שקיים סף נסתר בהסכם שבו, למשל, על השותף העסקי להוציא בלוק נוסף של אחסון נתונים AWS, או רכיב שירות אחר מאמזון שירותי האינטרנט, או ספק אחר של צד שלישי אחר. הם מעבירים את זה ללקוח בצורה של עלויות גבוהות יותר, וזה מעמיד את תג המחיר מחוץ להישג ידם של הלקוח.
במקרים אלה, מדידת השירותים שמקבלים מספקים עוזרת לשמור על סבירות הפרויקט. היקף הזכות במקום יבטיח כי עלויות הפרויקט לא יעלו על מה שניתן או סביר עבור המשרד המדובר.
חלופות קוד פתוח ותוכנות חופשיות
 כמה חלופות לתמיכה מלאה בספקים כוללות שימוש בתוכנת קוד פתוח, או אפילו תוכנה חופשית, לביצוע פרויקטים של הערות נתונים או תיוג. כאן יש מעין דרך אמצע בה חברות לא יוצרות הכל מאפס, אלא גם נמנעות מלהסתמך יותר מדי על ספקים מסחריים.
כמה חלופות לתמיכה מלאה בספקים כוללות שימוש בתוכנת קוד פתוח, או אפילו תוכנה חופשית, לביצוע פרויקטים של הערות נתונים או תיוג. כאן יש מעין דרך אמצע בה חברות לא יוצרות הכל מאפס, אלא גם נמנעות מלהסתמך יותר מדי על ספקים מסחריים.
מנטליות העשה זאת בעצמך של קוד פתוח היא בעצמה סוג של פשרה - מהנדסים ואנשים פנימיים יכולים לנצל את קהילת הקוד הפתוח, שם בסיסי משתמשים מבוזרים מציעים תמיכה בסיסית משלהם. זה לא יהיה כמו מה שתקבל מספק - לא תקבל סיוע קל 24 שעות ביממה או תשובות לשאלות בלי לעשות מחקר פנימי - אבל תג המחיר נמוך יותר.
אז השאלה הגדולה - מתי כדאי לרכוש כלי להערת נתונים:
כמו בסוגים רבים של פרויקטים של היי-טק, ניתוח מסוג זה - מתי לבנות ומתי לקנות - דורש מחשבה והתייחסות מסורתיים לאופן שמקורם ומנוהל על פרויקטים אלה. האתגרים העומדים בפני רוב החברות הקשורים לפרויקטים של AI / ML כאשר שוקלים את האפשרות "לבנות" הם לא רק חלקי הבנייה והפיתוח של הפרויקט. לעיתים קרובות יש עקומת למידה עצומה כדי להגיע אפילו למצב בו התפתחות AI / ML אמיתית יכולה להתרחש. עם צוותי AI / ML חדשים ויוזמות, מספר "האלמונים הלא ידועים" עולה בהרבה על מספר ה"לא ידועים. "
| לִבנוֹת | קנו |
|---|---|
יתרונות:
| יתרונות:
|
חסרונות:
| חסרונות:
|
כדי להפוך את הדברים לפשוטים עוד יותר, שקול את ההיבטים הבאים:
- כשאתה עובד על כמויות עצומות של נתונים
- כאשר אתה עובד על מגוון נתונים מגוון
- כאשר הפונקציות הקשורות למודלים או לפתרונות שלך עלולות להשתנות או להתפתח בעתיד
- כשיש לך מקרה מעורפל או כללי
- כאשר אתה זקוק למושג ברור לגבי ההוצאות הכרוכות בפריסת כלי הערת נתונים
- וכשאין לך כוח עבודה מתאים או מומחים מיומנים לעבוד על הכלים ומחפשים עקומת למידה מינימלית
אם התגובות שלך היו מנוגדות לתרחישים אלה, עליך להתמקד בבניית הכלי שלך.
כיצד לבחור את הכלי המתאים להערת נתונים עבור הפרויקט שלך
אם אתה קורא את זה, הרעיונות האלה נשמעים מרגשים, ובהחלט קל יותר לומר מאשר לעשות אותם. אז איך ניתן למנף את שלל כלי ההערות הקיימים כבר קיימים שם? לכן, השלב הבא הכרוך בשקילת הגורמים הקשורים לבחירת הכלי הנכון להערת נתונים.
שלא כמו לפני כמה שנים, השוק התפתח עם טונות של כלים לביאור נתונים בפועל כיום. לעסקים אפשרויות רבות יותר לבחור אחת על פי צרכיהם המובהקים. אבל כל כלי אחד מגיע עם מערכת יתרונות וחסרונות משלו. כדי לקבל החלטה נבונה, יש לנקוט בדרך אובייקטיבית מלבד דרישות סובייקטיביות.
בואו נסתכל על כמה גורמים מכריעים שעליכם לקחת בחשבון בתהליך.
הגדרת מקרה השימוש שלך
כדי לבחור את הכלי הנכון להערת נתונים, עליך להגדיר את מקרה השימוש שלך. עליך להבין אם הדרישה שלך כוללת טקסט, תמונה, וידאו, שמע או שילוב של כל סוגי הנתונים. ישנם כלים עצמאיים שתוכלו לקנות ויש כלים הוליסטיים המאפשרים לכם לבצע פעולות מגוונות על מערכי נתונים.
הכלים כיום הם אינטואיטיביים ומציעים לך אפשרויות מבחינת מתקני אחסון (רשת, מקומי או ענן), טכניקות ביאור (שמע, תמונה, תלת מימד ועוד) ועוד שלל היבטים. אתה יכול לבחור כלי המבוסס על הדרישות הספציפיות שלך.
קביעת תקני בקרת איכות
 זהו גורם מכריע שיש לקחת בחשבון כי המטרה והיעילות של מודלי ה- AI שלך תלויים בסטנדרטים האיכות שאתה קובע. כמו ביקורת, עליך לבצע בדיקות איכות של הנתונים שאתה מזין והתוצאות שהתקבלו כדי להבין אם המודלים שלך מאומנים בדרך הנכונה ולמטרות הנכונות. עם זאת, השאלה היא איך אתה מתכוון לקבוע תקני איכות?
זהו גורם מכריע שיש לקחת בחשבון כי המטרה והיעילות של מודלי ה- AI שלך תלויים בסטנדרטים האיכות שאתה קובע. כמו ביקורת, עליך לבצע בדיקות איכות של הנתונים שאתה מזין והתוצאות שהתקבלו כדי להבין אם המודלים שלך מאומנים בדרך הנכונה ולמטרות הנכונות. עם זאת, השאלה היא איך אתה מתכוון לקבוע תקני איכות?
כמו בסוגים רבים ושונים של עבודות, אנשים רבים יכולים לבצע הערות ותיוג נתונים אך הם עושים זאת בדרגות שונות של הצלחה. כשאתה מבקש שירות, אתה לא מאמת אוטומטית את רמת בקרת האיכות. לכן התוצאות משתנות.
אז, האם אתה רוצה לפרוס מודל קונצנזוס, שבו ביאורים מציעים משוב על אמצעים איכותיים ומתקנים ננקטים באופן מיידי? לחלופין, האם אתה מעדיף סקירת מדגם, תקני זהב או צומת על פני דגמי האיחוד?
תוכנית הקנייה הטובה ביותר תבטיח את בקרת האיכות מההתחלה על ידי קביעת סטנדרטים לפני שמוסכם על כל חוזה סופי. כאשר אתה קובע את זה, אתה לא צריך להתעלם גם שוליים שגיאה. לא ניתן להימנע לחלוטין מהתערבות ידנית מכיוון שמערכות חייבות לייצר שגיאות בשיעור של 3%. זה אכן לוקח עבודה מראש, אבל זה שווה את זה.
מי יעריר את הנתונים שלך?
הגורם העיקרי הבא מסתמך על מי שמביא הערות לנתונים שלך. האם אתה מתכוון לקיים צוות פנים או שאתה מעדיף להעביר אותו למיקור חוץ? אם אתה מבצע מיקור חוץ, יש חוקיות ואמצעי תאימות שאתה צריך לקחת בחשבון בגלל החששות לגבי פרטיות וסודיות הקשורים לנתונים. ואם יש לך צוות פנים, עד כמה הם יעילים בלימוד כלי חדש? מה הזמן שלך לשווק עם המוצר או השירות שלך? האם יש לך מדדי איכות וצוותים מתאימים לאישור התוצאות?
הספק נגד דיון שותפים
 ביאור נתונים הוא תהליך שיתופי. זה כרוך בתלות ומורכבויות כמו יכולת פעולה הדדית. המשמעות היא שצוותים מסוימים עובדים תמיד זה לצד זה ואחד הצוותים יכול להיות הספק שלך. זו הסיבה שהספק או השותף שאתה בוחר חשוב לא פחות מהכלי בו אתה משתמש לתיוג נתונים.
ביאור נתונים הוא תהליך שיתופי. זה כרוך בתלות ומורכבויות כמו יכולת פעולה הדדית. המשמעות היא שצוותים מסוימים עובדים תמיד זה לצד זה ואחד הצוותים יכול להיות הספק שלך. זו הסיבה שהספק או השותף שאתה בוחר חשוב לא פחות מהכלי בו אתה משתמש לתיוג נתונים.
עם גורם זה, יש לקחת בחשבון היבטים כמו היכולת לשמור על הנתונים והכוונות שלך, הכוונה לקבל ולעבוד על משוב, להיות פרואקטיבית מבחינת דרישות הנתונים, גמישות בתפעול ועוד לפני שאתה לוחץ ידיים לספק או לשותף. . כללנו גמישות מכיוון שדרישות הערות הנתונים אינן תמיד ליניאריות או סטטיות. הם עשויים להשתנות בעתיד ככל שתגדיל את העסק שלך עוד יותר. אם כרגע אתה מתמודד עם נתונים מבוססי טקסט בלבד, ייתכן שתרצה להוסיף הערות לנתוני שמע או וידאו תוך כדי שינוי גודל והתמיכה שלך צריכה להיות מוכנה להרחיב את אופקיהם איתך.
מעורבות ספק
אחת הדרכים להעריך את מעורבות הספקים היא התמיכה שתקבלו.
כל תוכנית קנייה צריכה להתחשב במרכיב זה. איך תיראה תמיכה בשטח? מי יהיו בעלי העניין והאנשים המצביעים משני צידי המשוואה?
ישנן גם משימות קונקרטיות שצריכות לאתר מהי מעורבות הספק (או תהיה). בפרט של הערת נתונים או תיוג נתונים, האם הספק יספק באופן פעיל את הנתונים הגולמיים, או לא? מי ישמש כמומחים בנושא, ומי יעסיק אותם כשכירים או כקבלנים עצמאיים?
מקרים לדוגמא
להלן כמה דוגמאות למקרה ספציפי המתייחסות לאופן בו ביאור נתונים ותיוג נתונים פועלים באמת בשטח. ב- Shaip אנו דואגים לספק את הרמות הגבוהות ביותר של איכות ותוצאות מעולות בהערת נתונים וסימון נתונים.
חלק ניכר מהדיון לעיל בהישגים סטנדרטיים להערות נתונים ולתיוג נתונים מגלה כיצד אנו ניגשים לכל פרויקט, ומה אנו מציעים לחברות ובעלי העניין שאיתם אנו עובדים.
חומרי לימוד מקרה שידגימו כיצד זה עובד:

בפרויקט של רישוי נתונים קליניים, צוות Shaip עיבד מעל 6,000 שעות שמע, הסיר את כל המידע הבריאותי המוגן (PHI) והשאיר תוכן תואם HIPAA למודלים לזיהוי דיבור בתחום הבריאות לעבודה.
במקרה מסוג זה, הקריטריונים ומיון ההישגים הם החשובים. הנתונים הגולמיים הם בצורה של אודיו, ויש צורך לזהות את הצדדים. לדוגמא, בשימוש בניתוח NER, המטרה הכפולה היא לבטל את הזיהוי והערת התוכן.
מחקר מקרה נוסף כולל עומק נתוני אימון AI לשיחה פרויקט שהשלמנו עם 3,000 בלשנים שעבדו על פני תקופה של 14 שבועות. זה הוביל לייצור נתוני הדרכה ב-27 שפות, על מנת לפתח עוזרים דיגיטליים רב לשוניים המסוגלים להתמודד עם אינטראקציות אנושיות במבחר רחב של שפות אם.
במחקר מקרה ספציפי זה ניכר הצורך להביא את האדם הנכון לכיסא הנכון. המספרים הגדולים של מומחי נושא ומפעילי קלט תוכן גרמו לכך שיש צורך בארגון וייעול פרוצדורלי בכדי לבצע את הפרויקט על ציר זמן מסוים. הצוות שלנו הצליח להכות את תקן התעשייה בפער רחב, באמצעות אופטימיזציה של איסוף הנתונים ותהליכים הבאים.
סוגים אחרים של מחקרי מקרה כוללים דברים כמו הכשרת בוטים והערת טקסטים לצורך למידת מכונה. שוב, בפורמט טקסט, עדיין חשוב לטפל בגורמים מזוהים על פי חוקי הפרטיות ולמיין את הנתונים הגולמיים כדי להשיג את התוצאות הממוקדות.
במילים אחרות, בעבודה על פני סוגי נתונים ופורמטים מרובים, שייפ הוכיח את אותה הצלחה חיונית על ידי יישום אותן שיטות ועקרונות גם על נתונים גולמיים וגם על תרחישים עסקיים לרישוי נתונים.