האם אתה מתכנן ליצור ולהקים מודל זיהוי פנים עבור מכשירים חכמים, פעולות בנקאיות או אופטימיזציה של בטיחות הציבור? אם כן, אז תצטרך להתמקד במערך הנתונים הנכונים להדרכה על פני כל דבר אחר. כן, להגדיר את מודל הבינה המלאכותית הנכון עם למידה עמוקה ואלגוריתמים של ML היא מאתגרת כשלעצמה, אבל ההגדרה של מקורות מידע ואיסוף נתונים לוקחת את העוגה. לאורך מאמר זה, אנו דנים במקרי השימוש של זיהוי פנים וכמה חשוב להזין מודלים של זיהוי פנים בסוג המידע הנכון. לאחר שסיימנו, אנו נוגעים בבסיס עם אסטרטגיות הערות נתונים לאופטימיזציה של מודלים של זיהוי פנים.
להלן שלושת הסעיפים העיקריים:
- לזיהוי פנים יש כמה יתרונות בעולם האמיתי. הם יכולים למנוע גניבות מחנויות, לזהות נעדרים, לשפר את איכות הפרסומות האישיות, לייעל את אכיפת החוק, להפוך את בתי הספר לאטומים ומאובטחים, לעקוב אחר נוכחות בכיתות ולעשות הרבה יותר. בשל היכולות המסיביות וההרחבה העצומה, שוק זיהוי הפנים העולמי צפוי להיות מוערך ב-7 מיליארד דולר עד 2024.
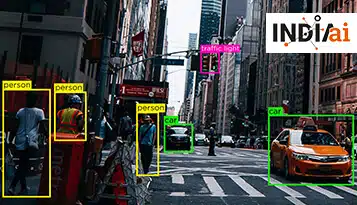
- חיוני להזין את דגמי זיהוי הפנים עם מערכי הנתונים הנכונים. גישה זו פירושה שיש לבדוק את הנתונים לצורך דיוק ואפס הטיה וחייבים להיות מסומנים כראוי.
- הערת נתונים או תיוג חשובים כדי לשפר עוד יותר את איכות הנתונים המוזנים. הגישה כוללת שימוש בתיבות תוחמות, פילוח סמנטי ואסטרטגיות הערות אחרות - המבוססות על מערך הנתונים המדובר.
לחץ כאן לקריאת מאמר זה: