

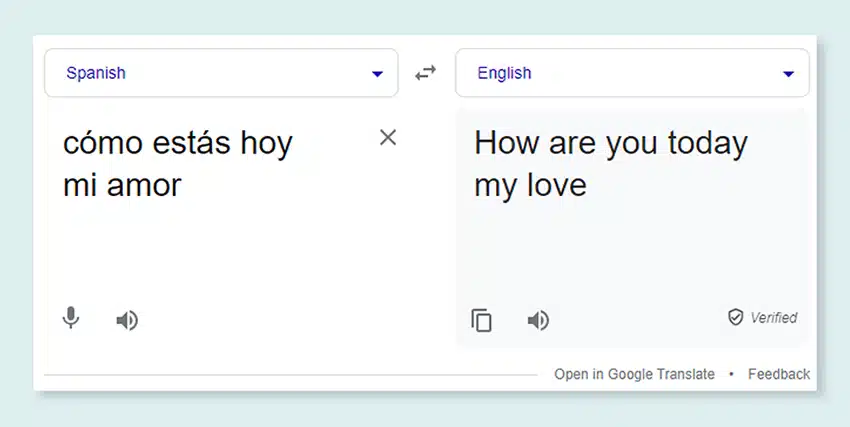
מהם מודלים של שפה גדולה?
מודלים של שפה גדולה (LLMs) הן מערכות בינה מלאכותית (AI) מתקדמות שנועדו לעבד, להבין וליצור טקסט דמוי אדם. הם מבוססים על טכניקות למידה עמוקה ומאומנים על מערכי נתונים מסיביים, המכילים בדרך כלל מיליארדי מילים ממקורות מגוונים כמו אתרי אינטרנט, ספרים ומאמרים. הכשרה נרחבת זו מאפשרת ללימודי תואר שני לתפוס את הניואנסים של שפה, דקדוק, הקשר ואפילו כמה היבטים של ידע כללי.
כמה לימודי LLM פופולריים, כמו GPT-3 של OpenAI, מעסיקים סוג של רשת עצבית הנקראת שנאי, המאפשרת להם להתמודד עם משימות שפה מורכבות במיומנות יוצאת דופן. מודלים אלה יכולים לבצע מגוון רחב של משימות, כגון:
- מענה על שאלות
- טקסט מסכם
- תרגום שפות
- יצירת תוכן
- אפילו מעורבות בשיחות אינטראקטיביות עם משתמשים
ככל ש-LLM ממשיכים להתפתח, יש להם פוטנציאל גדול לשיפור ואוטומציה של יישומים שונים בתעשיות, משירות לקוחות ויצירת תוכן ועד לחינוך ומחקר. עם זאת, הם גם מעלים חששות אתיים וחברתיים, כמו התנהגות מוטה או שימוש לרעה, שיש לטפל בהם עם התקדמות הטכנולוגיה.

דוגמאות פופולריות למודלים של שפה גדולה
להלן כמה דוגמאות בולטות של LLMs בשימוש נרחב בתעשייה אנכית שונים:
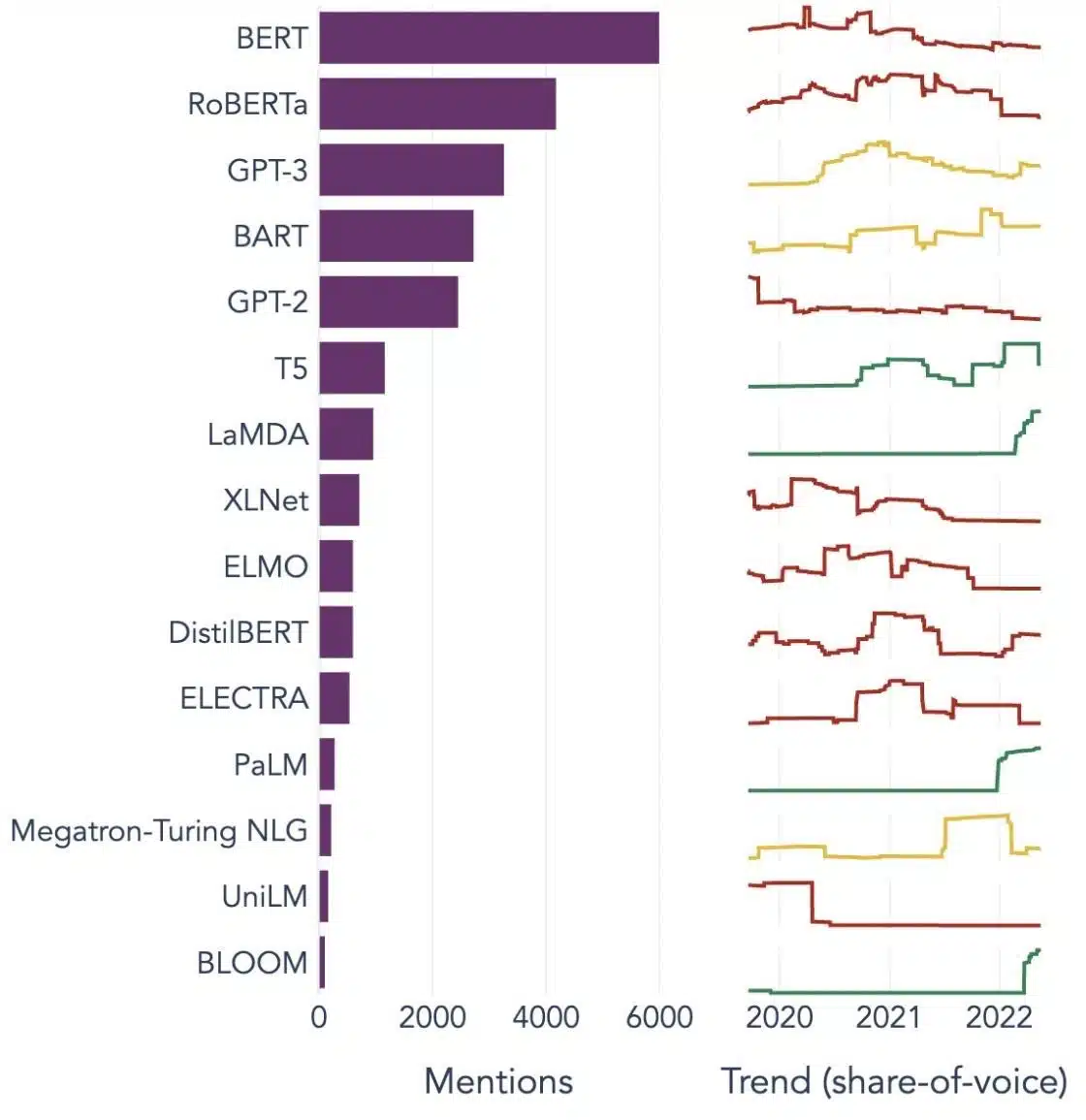
מקור תמונה: לקראת מדע נתונים
כיצד מאומנים דגמי LLM?
אימון מודלים של שפה גדולה (LLMs) הוא הישג לא קטן שכולל כמה שלבים חיוניים. להלן סקירה פשוטה של התהליך, שלב אחר שלב:
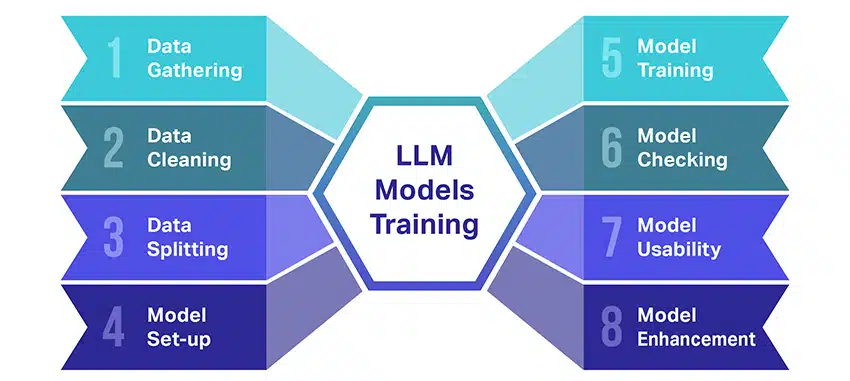
- איסוף נתוני טקסט: אימון LLM מתחיל באיסוף של כמות עצומה של נתוני טקסט. נתונים אלה יכולים להגיע מספרים, אתרים, מאמרים או פלטפורמות מדיה חברתית. המטרה היא ללכוד את המגוון העשיר של השפה האנושית.
- ניקוי הנתונים: לאחר מכן מסודרים נתוני הטקסט הגולמיים בתהליך הנקרא עיבוד מקדים. זה כולל משימות כמו הסרת תווים לא רצויים, פירוק הטקסט לחלקים קטנים יותר הנקראים אסימונים, והכנסת הכל לפורמט שאיתו המודל יכול לעבוד.
- פיצול הנתונים: לאחר מכן, הנתונים הנקיים מחולקים לשתי קבוצות. סט אחד, נתוני האימון, ישמש לאימון המודל. הסט השני, נתוני האימות, ישמש מאוחר יותר לבדיקת ביצועי המודל.
- הגדרת הדגם: לאחר מכן מוגדר המבנה של ה-LLM, המכונה הארכיטקטורה. זה כרוך בבחירת סוג הרשת העצבית והחלטה על פרמטרים שונים, כמו מספר השכבות והיחידות הנסתרות בתוך הרשת.
- אימון הדגם: האימון בפועל מתחיל כעת. מודל ה-LLM לומד על ידי התבוננות בנתוני האימון, ביצוע תחזיות על סמך מה שלמד עד כה, ולאחר מכן התאמת הפרמטרים הפנימיים שלו כדי לצמצם את ההבדל בין התחזיות שלו לנתונים בפועל.
- בדיקת הדגם: הלמידה של מודל ה-LLM נבדקת באמצעות נתוני האימות. זה עוזר לראות עד כמה המודל מתפקד ולשנות את הגדרות הדגם לביצועים טובים יותר.
- שימוש במודל: לאחר הדרכה והערכה, מודל ה-LLM מוכן לשימוש. כעת ניתן לשלב אותו באפליקציות או במערכות שבהן הוא יפיק טקסט על סמך קלט חדש שניתן לו.
- שיפור המודל: לבסוף, תמיד יש מקום לשיפור. ניתן לשכלל את מודל ה-LLM עם הזמן, באמצעות נתונים מעודכנים או התאמת הגדרות על סמך משוב ושימוש בעולם האמיתי.
זכור, תהליך זה דורש משאבי חישוב משמעותיים, כגון יחידות עיבוד חזקות ואחסון גדול, כמו גם ידע מיוחד בלמידת מכונה. לכן זה נעשה בדרך כלל על ידי ארגוני מחקר ייעודיים או חברות עם גישה לתשתית ולמומחיות הדרושים.
האם ה-LLM מסתמך על למידה מפוקחת או לא מפוקחת?
מודלים של שפה גדולים מאומנים בדרך כלל באמצעות שיטה הנקראת למידה מפוקחת. במילים פשוטות, זה אומר שהם לומדים מדוגמאות שמראות להם את התשובות הנכונות.
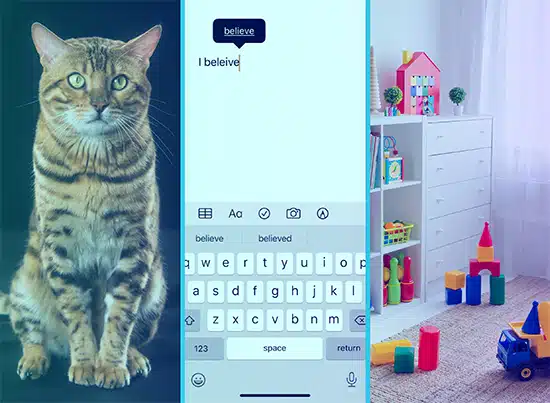 תאר לעצמך שאתה מלמד ילד מילים על ידי הצגת תמונות. אתה מראה להם תמונה של חתול ואומר "חתול", והם לומדים לקשר את התמונה הזו למילה. כך עובדת למידה מפוקחת. המודל מקבל הרבה טקסט ("התמונות") והפלטים המתואמים ("המילים"), והוא לומד להתאים אותם.
תאר לעצמך שאתה מלמד ילד מילים על ידי הצגת תמונות. אתה מראה להם תמונה של חתול ואומר "חתול", והם לומדים לקשר את התמונה הזו למילה. כך עובדת למידה מפוקחת. המודל מקבל הרבה טקסט ("התמונות") והפלטים המתואמים ("המילים"), והוא לומד להתאים אותם.
לכן, אם אתה מאכיל LLM במשפט, הוא מנסה לחזות את המילה או הביטוי הבא על סמך מה שהוא למד מהדוגמאות. בדרך זו, הוא לומד כיצד ליצור טקסט הגיוני ומתאים להקשר.
עם זאת, לפעמים גם לימודי תואר שני משתמשים במעט למידה ללא פיקוח. זה כמו לתת לילד לחקור חדר מלא בצעצועים שונים וללמוד עליהם בעצמו. המודל מסתכל על נתונים ללא תווית, דפוסי למידה ומבנים מבלי שיאמרו לו את התשובות "הנכונות".
למידה מפוקחת משתמשת בנתונים שסומנו עם קלט ופלט, בניגוד ללמידה לא מפוקחת, שאינה משתמשת בנתוני פלט מסומנים.
בקצרה, לימודי LLM מאומנים בעיקר באמצעות למידה מפוקחת, אך הם יכולים גם להשתמש בלמידה ללא פיקוח כדי לשפר את היכולות שלהם, כגון לניתוח חקרני והפחתת מימדים.
מהו נפח הנתונים (בGB) הדרוש כדי לאמן מודל שפה גדול?
עולם האפשרויות לזיהוי נתוני דיבור ויישומי קול הוא עצום, והם נמצאים בשימוש במספר תעשיות עבור שפע של יישומים.
אימון מודל שפה גדול אינו תהליך שמתאים לכולם, במיוחד כשמדובר בנתונים הדרושים. זה תלוי בכמה דברים:
- עיצוב הדגם.
- איזה עבודה הוא צריך לעשות?
- סוג הנתונים שבהם אתה משתמש.
- כמה טוב אתה רוצה שהוא יפעל?
עם זאת, אימון לימודי LLM דורש בדרך כלל כמות עצומה של נתוני טקסט. אבל על כמה מסיבי אנחנו מדברים? ובכן, תחשוב הרבה מעבר לג'יגה-בייט (GB). בדרך כלל אנו מסתכלים על טרה-בייט (TB) או אפילו פטה-בייט (PB) של נתונים.
שקול את GPT-3, אחד ה-LLMs הגדולים ביותר בסביבה. זה מאומן על 570 GB של נתוני טקסט. LLMs קטנים יותר עשויים להזדקק לפחות - אולי 10-20 GB או אפילו 1 GB של ג'יגה-בייט - אבל זה עדיין הרבה.

אבל זה לא קשור רק לגודל הנתונים. גם האיכות חשובה. הנתונים צריכים להיות נקיים ומגוונים כדי לעזור למודל ללמוד ביעילות. ואתה לא יכול לשכוח חלקי מפתח אחרים בפאזל, כמו כוח המחשוב שאתה צריך, האלגוריתמים שבהם אתה משתמש לאימון והגדרת החומרה שיש לך. כל הגורמים הללו ממלאים חלק גדול בהכשרת LLM.
עלייתם של מודלים גדולים של שפה: מדוע הם חשובים
לימודי תואר שני הם כבר לא רק מושג או ניסוי. הם ממלאים יותר ויותר תפקיד קריטי בנוף הדיגיטלי שלנו. אבל למה זה קורה? מה הופך את לימודי הלימוד הללו לכל כך חשובים? בואו נעמיק בכמה גורמים מרכזיים.
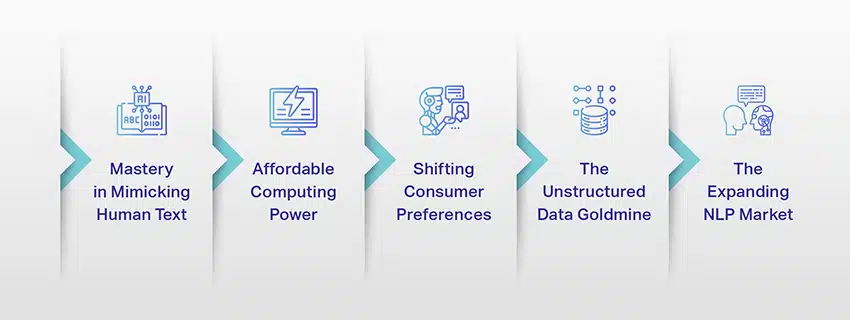
שליטה בחיקוי טקסט אנושי
לימודי LLM שינו את הדרך בה אנו מטפלים במשימות מבוססות שפה. מודלים אלה, שנבנו באמצעות אלגוריתמים חזקים של למידת מכונה, מצוידים ביכולת להבין את הניואנסים של השפה האנושית, כולל הקשר, רגש ואפילו סרקזם, במידה מסוימת. היכולת הזו לחקות את השפה האנושית היא לא רק חידוש, יש לה השלכות משמעותיות.
יכולות יצירת הטקסט המתקדמות של LLM יכולות לשפר הכל, החל מיצירת תוכן ועד לאינטראקציות עם שירות לקוחות.
תאר לעצמך שאתה יכול לשאול עוזר דיגיטלי שאלה מורכבת ולקבל תשובה לא רק הגיונית, אלא גם קוהרנטית, רלוונטית ומועברת בנימה של שיחה. זה מה שמאפשרים לימודי LLM. הם מזינים אינטראקציה אינטואיטיבית ומרתקת יותר בין אדם למכונה, מעשירים את חוויות המשתמש ודמוקרטיות את הגישה למידע.
כוח מחשוב במחיר סביר
עלייתם של LLMs לא הייתה מתאפשרת ללא התפתחויות מקבילות בתחום המחשוב. ליתר דיוק, הדמוקרטיזציה של משאבים חישוביים מילאה תפקיד משמעותי בהתפתחות ואימוץ של LLMs.
פלטפורמות מבוססות ענן מציעות גישה חסרת תקדים למשאבי מחשוב בעלי ביצועים גבוהים. בדרך זו, אפילו ארגונים בקנה מידה קטן וחוקרים עצמאיים יכולים להכשיר מודלים מתוחכמים של למידת מכונה.
יתרה מכך, שיפורים ביחידות העיבוד (כמו GPUs ו-TPUs), בשילוב עם עליית המחשוב המבוזר, אפשרו להכשיר מודלים עם מיליארדי פרמטרים. נגישות מוגברת זו של כוח מחשוב מאפשרת את הצמיחה וההצלחה של LLMs, מה שמוביל ליותר חדשנות ויישומים בתחום.
שינוי העדפות צרכנים
הצרכנים היום לא רוצים רק תשובות; הם רוצים אינטראקציות מרתקות וניתנות לקשר. ככל שיותר אנשים גדלים באמצעות טכנולוגיה דיגיטלית, ניכר שהצורך בטכנולוגיה שמרגישה טבעית וכמו אנושית יותר הולך וגדל. LLMs מציעים הזדמנות שאין כמותה לעמוד בציפיות הללו. על ידי יצירת טקסט דמוי אדם, המודלים הללו יכולים ליצור חוויות דיגיטליות מרתקות ודינמיות, שיכולות להגביר את שביעות הרצון והנאמנות של המשתמשים. בין אם מדובר בצ'אטבוטים של בינה מלאכותית המספקים שירות לקוחות או עוזרים קוליים המספקים עדכוני חדשות, אנשי LLM פותחים עידן של בינה מלאכותית שמבינה אותנו טוב יותר.
מכרה הזהב של הנתונים הלא מובנים
נתונים לא מובנים, כמו מיילים, פוסטים במדיה חברתית וביקורות של לקוחות, הם אוצר של תובנות. ההערכה היא שנגמר 80% של הנתונים הארגוניים אינו מובנה וגדל בקצב של 55% לשנה. נתונים אלה הם מכרה זהב לעסקים אם הם ממונפים אותם כראוי.
LLMs נכנסים כאן לפעולה, עם היכולת שלהם לעבד ולהבין נתונים כאלה בקנה מידה. הם יכולים להתמודד עם משימות כמו ניתוח סנטימנטים, סיווג טקסט, חילוץ מידע ועוד, ובכך לספק תובנות חשובות.
בין אם זה זיהוי מגמות מפוסטים במדיה חברתית או מדידת סנטימנט לקוחות מביקורות, LLMs עוזרים לעסקים לנווט בכמות הגדולה של נתונים לא מובנים ולקבל החלטות מונעות נתונים.
שוק ה-NLP המתרחב
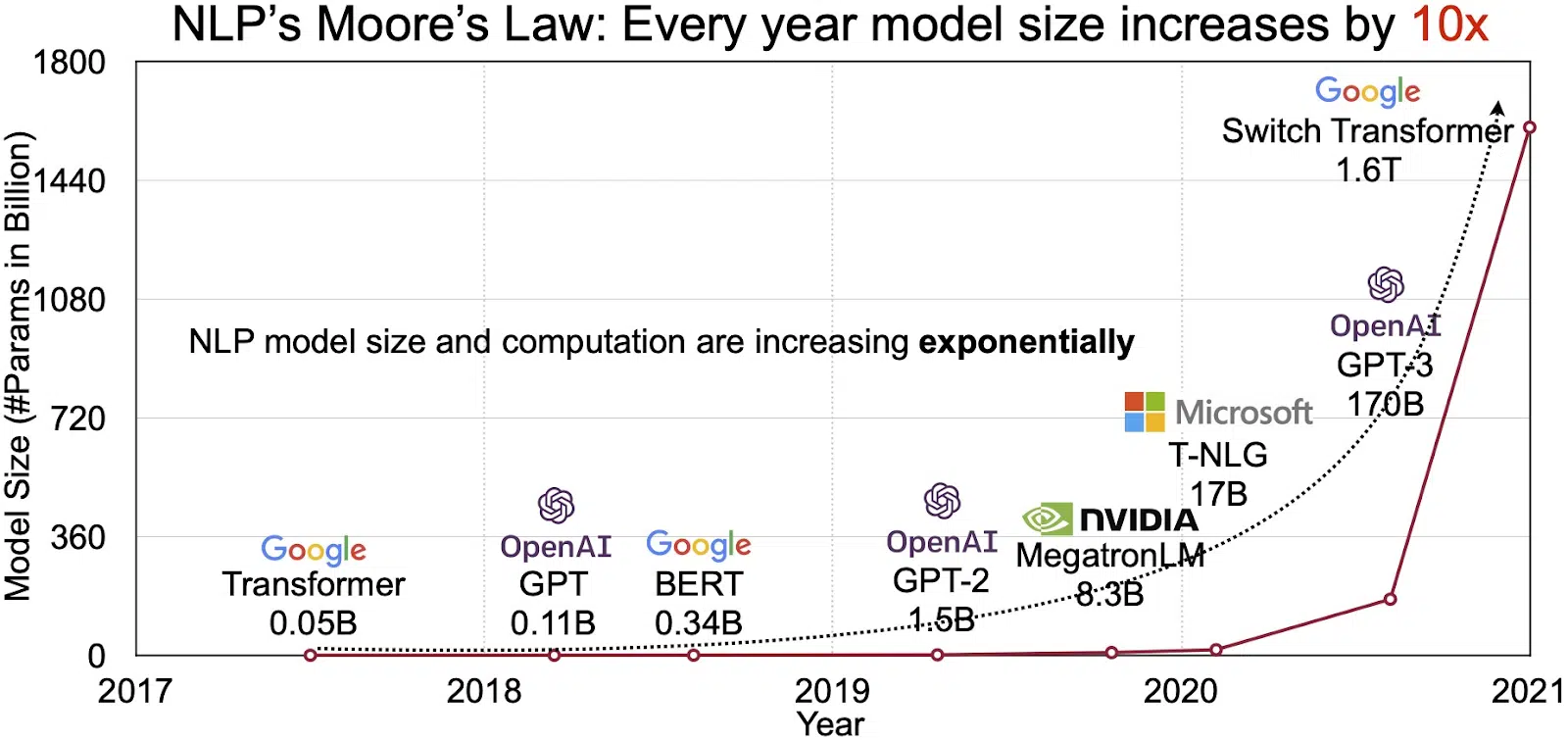
הפוטנציאל של LLMs בא לידי ביטוי בשוק ההולך וגדל במהירות של עיבוד שפה טבעית (NLP). אנליסטים מעריכים את שוק ה-NLP להתרחב ממנו 11 מיליארד דולר ב-2020 עד למעלה מ-35 מיליארד דולר ב-2026. אבל לא רק גודל השוק מתרחב. גם הדגמים עצמם גדלים, הן בגודל הפיזי והן במספר הפרמטרים שהם מטפלים בהם. האבולוציה של LLMs לאורך השנים, כפי שניתן לראות באיור למטה (מקור תמונה: קישור), מדגישה את המורכבות והיכולת הגוברת שלהם.
מקרי שימוש פופולריים של דגמי שפה גדולים
להלן כמה ממקרי השימוש המובילים והנפוצים ביותר של LLM:
- יצירת טקסט בשפה טבעית: מודלים של שפה גדולה (LLMs) משלבים את הכוח של בינה מלאכותית ובלשנות חישובית כדי לייצר באופן אוטונומי טקסטים בשפה טבעית. הם יכולים לתת מענה לצרכים מגוונים של משתמשים כגון כתב מאמרים, יצירת שירים או שיחות עם משתמשים.
- תרגום באמצעות מכונות: ניתן להשתמש ב-LLM ביעילות כדי לתרגם טקסט בין כל צמד שפות. מודלים אלה מנצלים אלגוריתמי למידה עמוקה כמו רשתות עצביות חוזרות כדי להבין את המבנה הלשוני של שפות המקור והיעד, ובכך להקל על התרגום של טקסט המקור לשפה הרצויה.
- יצירת תוכן מקורי: LLMs פתחו דרכים למכונות ליצור תוכן מגובש והגיוני. ניתן להשתמש בתוכן זה ליצירת פוסטים בבלוג, מאמרים וסוגים אחרים של תוכן. המודלים מנצלים את חווית הלמידה העמוקה שלהם כדי לעצב ולבנות את התוכן בצורה חדשנית וידידותית למשתמש.
- ניתוח רגשות: יישום מסקרן אחד של מודלים של שפה גדולה הוא ניתוח סנטימנטים. בכך, המודל מאומן לזהות ולסווג מצבים רגשיים ותחושות הקיימים בטקסט המוער. התוכנה יכולה לזהות רגשות כמו חיוביות, שליליות, ניטרליות ותחושות מורכבות אחרות. זה יכול לספק תובנות חשובות לגבי משוב לקוחות ודעות לגבי מוצרים ושירותים שונים.
- הבנה, סיכום וסיווג טקסט: LLMs מקימים מבנה בר-קיימא עבור תוכנת AI לפרש את הטקסט ואת ההקשר שלו. על ידי הנחיית המודל להבין ולבחון כמויות עצומות של נתונים, LLMs מאפשרים למודלים של AI להבין, לסכם ואפילו לסווג טקסט בצורות ודפוסים מגוונים.
- מענה לשאלות: מודלים של שפה גדולים מציידים את מערכות המענה לשאלות (QA) עם יכולת לתפוס ולהגיב במדויק לשאילתת השפה הטבעית של המשתמש. דוגמאות פופולריות למקרה שימוש זה כוללות ChatGPT ו-BERT, שבודקות את ההקשר של שאילתה ומסננים אוסף עצום של טקסטים כדי לספק תשובות רלוונטיות לשאלות משתמשים.

תיוג חלקי דיבור (POS).
מילים במשפטים מתויגות בתפקוד הדקדוק שלהן, כגון פעלים, שמות עצם, תארים וכו'. תהליך זה מסייע למודל בהבנת הדקדוק והקישורים בין מילים.

זיהוי ישויות בשם (NER)
ישויות עם שם כמו ארגונים, מיקומים ואנשים בתוך משפט מסומנות. תרגיל זה מסייע למודל בפירוש המשמעויות הסמנטיות של מילים וביטויים ומספק תגובות מדויקות יותר.

ניתוח הסנטימנט
לנתוני טקסט מוקצות תוויות סנטימנט כמו חיוביות, ניטרליות או שליליות, ועוזרות למודל לתפוס את הטון הרגשי של משפטים. זה שימושי במיוחד במענה לשאילתות המערבות רגשות ודעות.
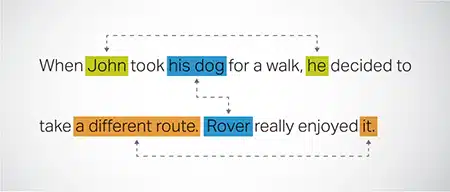
רזולוציית Coreference
זיהוי ופתרון מקרים שבהם מתייחסים לאותה ישות בחלקים שונים של טקסט. שלב זה עוזר למודל להבין את ההקשר של המשפט, ובכך מוביל לתגובות קוהרנטיות.
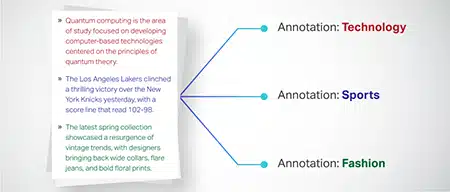
סיווג טקסט
נתוני טקסט מסווגים לקבוצות מוגדרות מראש כמו ביקורות על מוצרים או כתבות חדשותיות. זה מסייע למודל להבחין בז'אנר או נושא הטקסט, ויוצר תגובות רלוונטיות יותר.
ההצעה של שייפ
שייפ מציעה מגוון רחב של שירותים כדי לעזור לארגונים לנהל, לנתח ולהפיק את המרב מהנתונים שלהם.
גירוד אינטרנט
שירות מרכזי אחד שמציעה שייפ הוא גירוד נתונים. זה כרוך בחילוץ נתונים מכתובות URL ספציפיות לדומיין. על ידי שימוש בכלים וטכניקות אוטומטיות, שייפ יכולה לגרד במהירות וביעילות כמויות גדולות של נתונים מאתרים שונים, מדריכי מוצרים, תיעוד טכני, פורומים מקוונים, ביקורות מקוונות, נתוני שירות לקוחות, מסמכי רגולציה בתעשייה וכו'. תהליך זה עשוי להיות בעל ערך רב עבור עסקים כאשר איסוף נתונים רלוונטיים וספציפיים ממספר רב של מקורות.

מכונת תרגום
פתח מודלים באמצעות מערכי נתונים רב לשוניים נרחבים בשילוב עם תעתיקים מתאימים לתרגום טקסט בשפות שונות. תהליך זה מסייע בפירוק מכשולים לשוניים ומקדם את נגישות המידע.
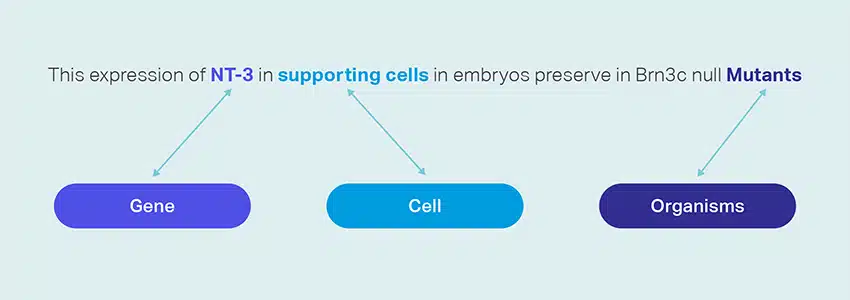
מיצוי ויצירה של טקסונומיה
שייפ יכול לעזור בחילוץ ויצירה של טקסונומיה. זה כולל סיווג וסיווג נתונים לפורמט מובנה המשקף את היחסים בין נקודות נתונים שונות. זה יכול להיות שימושי במיוחד עבור עסקים בארגון הנתונים שלהם, מה שהופך אותם לנגישים יותר וקלים יותר לניתוח. לדוגמה, בעסק של מסחר אלקטרוני, נתוני מוצרים עשויים להיות מסווגים לפי סוג מוצר, מותג, מחיר וכו', מה שמקל על הלקוחות לנווט בקטלוג המוצרים.
איסוף נתונים
שירותי איסוף הנתונים שלנו מספקים נתונים קריטיים בעולם האמיתי או סינתטיים הנחוצים לאימון אלגוריתמי בינה מלאכותית ושיפור הדיוק והיעילות של המודלים שלך. הנתונים הם חסרי משוחד, מקור אתי ואחראי תוך שמירה על פרטיות ואבטחת הנתונים.

שאלה ותשובה
תשובות לשאלות (QA) הוא תת-תחום של עיבוד שפה טבעית המתמקד במענה אוטומטי על שאלות בשפה אנושית. מערכות QA מאומנות על טקסט וקוד נרחבים, מה שמאפשר להן לטפל בסוגים שונים של שאלות, כולל שאלות עובדתיות, הגדרות ודעות מבוססות. ידע בתחום הוא חיוני לפיתוח מודלים של QA המותאמים לתחומים ספציפיים כמו תמיכת לקוחות, שירותי בריאות או שרשרת אספקה. עם זאת, גישות QA גנרטיביות מאפשרות למודלים ליצור טקסט ללא ידע בתחום, תוך הסתמכות על הקשר בלבד.
צוות המומחים שלנו יכול ללמוד בקפידה מסמכים או מדריכים מקיפים כדי ליצור צמדי שאלה-תשובה, מה שמקל על היצירה של AI Generative עבור עסקים. גישה זו יכולה להתמודד ביעילות עם פניות משתמשים על ידי כריית מידע רלוונטי מגוף נרחב. המומחים המוסמכים שלנו מבטיחים ייצור של צמדי שאלות ותשובות איכותיות המתפרשות על פני נושאים ותחומים מגוונים.

סיכום טקסטים
המומחים שלנו מסוגלים לזקק שיחות מקיפות או דיאלוגים ארוכים, לספק סיכומים תמציתיים ומלאי תובנות מנתוני טקסט נרחבים.

יצירת טקסט
אימון מודלים באמצעות מערך נתונים רחב של טקסט בסגנונות מגוונים, כמו מאמרי חדשות, סיפורת ושירה. מודלים אלה יכולים לאחר מכן ליצור סוגים שונים של תוכן, כולל מאמרים חדשותיים, רשומות בבלוגים או פוסטים במדיה חברתית, ומציעים פתרון חסכוני וחסכון בזמן ליצירת תוכן.
זיהוי דיבור
לפתח מודלים המסוגלים להבין את השפה המדוברת עבור יישומים שונים. זה כולל עוזרים המופעלים בקול, תוכנת הכתבה וכלי תרגום בזמן אמת. התהליך כולל שימוש במערך נתונים מקיף המורכב מהקלטות אודיו של שפה מדוברת, בשילוב עם התמלילים המתאימים להם.

המלצות למוצר
פתח מודלים באמצעות מערכי נתונים נרחבים של היסטוריית קניות של לקוחות, כולל תוויות המצביעות על המוצרים שהלקוחות נוטים לרכוש. המטרה היא לספק הצעות מדויקות ללקוחות, ובכך להגביר את המכירות ולשפר את שביעות רצון הלקוחות.
כיתוב תמונה
עשה מהפכה בתהליך פרשנות התמונה שלך עם שירות כיתוב תמונה המתקדם שלנו, מונע בינה מלאכותית. אנו מחדירים חיוניות לתמונות על ידי הפקת תיאורים מדויקים ומשמעותיים מבחינה הקשרית. זה סולל את הדרך לאפשרויות מעורבות ואינטראקציה חדשניות עם התוכן החזותי שלך עבור הקהל שלך.

הכשרת שירותי טקסט לדיבור
אנו מספקים מערך נתונים נרחב המורכב מהקלטות אודיו של דיבור אנושי, אידיאלי לאימון מודלים של AI. מודלים אלה מסוגלים להפיק קולות טבעיים ומושכים עבור היישומים שלך, ובכך לספק חווית סאונד ייחודית וסוחפת למשתמשים שלך.



