
האינטרנט פתח את הדלתות לאנשים המביעים בחופשיות את דעותיהם, דעותיהם והצעותיהם על כמעט כל דבר בעולם על מדיה חברתית, אתרי אינטרנט ובלוגים. בנוסף להבעת דעותיהם, אנשים (לקוחות) משפיעים גם על החלטות הקנייה של אחרים. הסנטימנט, בין אם שלילי או חיובי, הוא קריטי עבור כל עסק או מותג שמודאגים ממכירות המוצרים או השירותים שלו.
לעזור לעסקים לכרות את ההערות לשימוש עסקי עיבוד שפה טבעית. אחד מכל ארבעה עסקים יש תוכניות ליישם טכנולוגיית NLP במהלך השנה הבאה כדי להניע את ההחלטות העסקיות שלהם. באמצעות ניתוח סנטימנטים, NLP עוזר לעסקים להפיק תובנות ניתנות לפירוש מנתונים גולמיים ובלתי מובנים.
כריית דעות או ניתוח הסנטימנט היא טכניקת NLP המשמשת לזיהוי הסנטימנט המדויק - חיובי, שלילי או ניטרלי - קשור להערות ומשוב. בעזרת NLP, מילות מפתח בהערות מנותחות כדי לקבוע את המילים החיוביות או השליליות הכלולות במילת המפתח.
סנטימנטים מקבלים ניקוד על מערכת קנה מידה המקצה ציוני סנטימנט לרגשות בקטע טקסט (קובע את הטקסט כחיובי או שלילי).
מהו ניתוח סנטימנט רב לשוני?

כפי שהשם מרמז, ניתוח סנטימנטים רב לשוני היא הטכניקה של ביצוע ציוני סנטימנט עבור יותר משפה אחת. עם זאת, זה לא כל כך פשוט. התרבות, השפה והחוויות שלנו משפיעות רבות על התנהגות הקנייה והרגשות שלנו. ללא הבנה טובה של השפה, ההקשר והתרבות של המשתמש, אי אפשר להבין במדויק את כוונות המשתמש, הרגשות והפרשנויות.
אמנם אוטומציה היא התשובה להרבה מהצרות המודרניות שלנו, מכונת תרגום תוכנה לא תוכל לקלוט את הניואנסים של השפה, דיבורים, דקויות והתייחסויות תרבותיות בהערות וב ביקורות מוצר זה מתרגם. הכלי ML עשוי לתת לך תרגום, אבל ייתכן שהוא לא יהיה שימושי. זו הסיבה מדוע נדרש ניתוח סנטימנט רב לשוני.
מדוע יש צורך בניתוח סנטימנטים רב לשוני?
רוב העסקים משתמשים באנגלית כאמצעי התקשורת שלהם, אבל זה לא נמצא בשימוש על ידי רוב הצרכנים ברחבי העולם.
לפי אתנולוג, כ-13% מאוכלוסיית העולם דוברת אנגלית. בנוסף, המועצה הבריטית קובעת כי לכ-25% מאוכלוסיית העולם יש הבנה נאותה באנגלית. אם להאמין למספרים האלה, אז חלק גדול מהצרכנים מקיימים אינטראקציה זה עם זה ועם העסק בשפה שאינה אנגלית.
אם המטרה העיקרית של עסקים היא לשמור על בסיס הלקוחות שלהם ללא פגע ולמשוך לקוחות חדשים, עליו להבין היטב את דעות הלקוחות שלהם המובעות ב שפת אם. סקירה ידנית של כל הערה או תרגום שלה לאנגלית הוא תהליך מסורבל שלא יניב תוצאות אפקטיביות.
פתרון בר קיימא הוא פיתוח רב לשוני מערכות ניתוח סנטימנטים שמזהים ומנתחים דעות, רגשות והצעות של לקוחות ברשתות חברתיות, פורומים, סקרים ועוד.
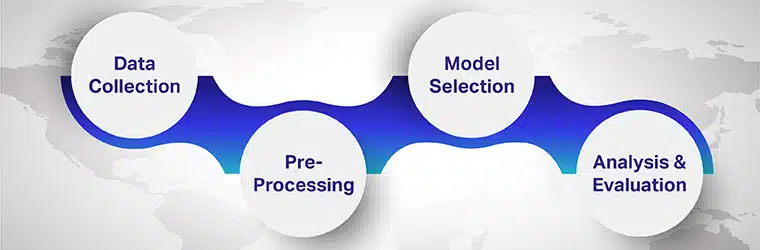
שלבים לביצוע ניתוח סנטימנט רב לשוני
ניתוח סנטימנטים, לא משנה אם בשפה אחת או שפות מרובות, הוא תהליך הדורש יישום של מודלים של למידת מכונה, עיבוד שפה טבעית וטכניקות ניתוח נתונים כדי לחלץ ניקוד סנטימנט רב לשוני מהנתונים.
השלבים הכרוכים בניתוח סנטימנט רב לשוני הם
שלב 1: איסוף נתונים
איסוף נתונים הוא הצעד הראשון ביישום ניתוח סנטימנטים. כדי ליצור רב לשוני מודל ניתוח סנטימנטים, חשוב לרכוש נתונים במגוון שפות. הכל יהיה תלוי באיכות הנתונים שנאספו, יביאו הערות ותיוג. אתה יכול לצייר נתונים ממשקי API, מאגרי קוד פתוח ומפרסמים.
שלב 2: עיבוד מקדים
יש לנקות את נתוני האינטרנט שנאספו, וללקט מהם מידע. יש להסיר את חלקי הטקסט שאינם מעבירים משמעות מסוימת, כגון 'ה' 'יש' ועוד. יתר על כן, יש לקבץ את הטקסט לקבוצות מילים כדי להיות מסווגות כדי להעביר משמעות חיובית או שלילית.
כדי לשפר את איכות הסיווג, יש לנקות את התוכן מרעשים, כגון תגי HTML, פרסומות ותסריטים. השפה, הלקסיקון והדקדוק שבהם משתמשים אנשים שונים בהתאם לרשת החברתית. חשוב לנרמל תוכן כזה ולהכין אותו לעיבוד מקדים.
שלב קריטי נוסף בעיבוד מקדים הוא שימוש בעיבוד שפה טבעית כדי לפצל משפטים, להסיר מילות עצירה, לתייג חלקי דיבור, להפוך מילים לצורת השורש שלהן ולהפוך מילים לסמלים ולטקסט.
שלב 3: בחירת דגם
מודל מבוסס כללים: השיטה הפשוטה ביותר של ניתוח סמנטי רב לשוני מבוססת על כללים. האלגוריתם מבוסס הכללים מבצע את הניתוח בהתבסס על קבוצה של כללים שנקבעו מראש שתוכנתו על ידי המומחים.
הכלל יכול לציין מילים או ביטויים שהם חיוביים או שליליים. אם אתה לוקח ביקורת על מוצר או שירות, למשל, היא יכולה להכיל מילים חיוביות או שליליות כגון 'נהדר', 'איטי', 'חכה' ו'שימושי'. שיטה זו מקלה על סיווג מילים, אך היא עלולה לסווג באופן שגוי מילים מסובכות או פחות תכופות.
דגם אוטומטי: המודל האוטומטי מבצע ניתוח סנטימנטים רב לשוני ללא מעורבות של מנחים אנושיים. למרות שמודל למידת המכונה נבנה תוך שימוש במאמץ אנושי, הוא יכול לעבוד באופן אוטומטי כדי לספק תוצאות מדויקות לאחר פיתוח.
נתוני הבדיקה מנותחים, וכל הערה מסומנת באופן ידני כחיובית או שלילית. לאחר מכן מודל ה-ML ילמד מנתוני הבדיקה על ידי השוואת הטקסט החדש להערות הקיימות וסיווגם.
שלב 4: ניתוח והערכה
ניתן לשפר ולשפר את המודלים מבוססי החוקים ולמידת המכונה לאורך זמן וניסיון. ניתן לעדכן לקסיקון של מילים בשימוש פחות תכוף או ציונים חיים עבור סנטימנטים רב לשוניים לסיווג מהיר ומדויק יותר.
אתגר התרגום
האם תרגום לא מספיק? בעצם לא!
תרגום כולל העברת טקסט או קבוצות טקסט משפה אחת ומציאת מקבילה בשפה אחרת. עם זאת, התרגום אינו פשוט ואינו יעיל.
הסיבה לכך היא שבני אדם משתמשים בשפה לא רק כדי לתקשר את הצרכים שלהם אלא גם כדי להביע את רגשותיהם. יתרה מכך, ישנם הבדלים בולטים בין שפות שונות, כגון אנגלית, הינדית, מנדרינית ותאילנדית. הוסף לתמהיל הספרותי הזה את השימוש ברגשות, סלנג, ניבים, סרקזם ואימוג'ים. לא ניתן לקבל תרגום מדויק של הטקסט.
כמה מהאתגרים העיקריים של מכונת תרגום יש לו
- סובייקטיביות
- הקשר
- סלנג וניבים
- סרקזם
- השוואות
- אֲדִישׁוּת
- אמוג'ים ושימוש מודרני במילים.
מבלי להבין במדויק את המשמעות המיועדת של הביקורות, ההערות והתקשורת לגבי המוצרים, המחירים, השירותים, התכונות והאיכות שלהם, עסקים לא יוכלו להבין את צרכיהם ודעותיהם של הלקוחות.
ניתוח סנטימנטים רב לשוני הוא תהליך מאתגר. לכל שפה יש את הלקסיקון, התחביר, המורפולוגיה והפונולוגיה הייחודיים לה. תוסיפו לזה את התרבות, הסלנג, רגשות שהובעו, סרקזם וטונאליות, וקיבלת לעצמך פאזל מאתגר שזקוק לפתרון ML יעיל המופעל על ידי בינה מלאכותית.
יש צורך במערך נתונים רב שפות מקיף כדי לפתח רב לשוני חזק כלי ניתוח סנטימנט שיכולים לעבד ביקורות ולספק תובנות חזקות לעסקים. שייפ היא מובילת השוק באספקת מערכי נתונים מותאמים אישית, מתויגים, מוערים בכמה שפות המסייעים בפיתוח יעיל ומדויק פתרונות ניתוח סנטימנטים רב לשוניים.


